ADO's Voice Screen
- API response examples
- Introduction to the Emotion Logic AI Platform
- About Layered Voice Analysis (LVA™)
- Emotion Logic platform's basics
- FeelGPT Advisors System
- AppTone Questionnaires System
- Developer's zone
- Audio Analysis API
- API response examples
- Standard call center response sample
- Call center sales response sample
- Call center risk sample response
- API Error and warning codes
- "Analyze Now" APIs
- Obtaining advisor id
- AppTone Get Questionnaires List
- Docker installation and maintenance
- Real-time analysis (streaming)
- Sample code - avoid promises
API response examples
Risk assessment - questionnaire base
Call center sales response sample






Introduction to the Emotion Logic AI Platform
Emotion-Logic is a pioneering platform designed to empower two core user groups:
- Business professionals seeking ready-to-use tools for emotion analysis.
- Developers aiming to integrate advanced emotional intelligence into their own solutions.
- Academic researchers exploring emotional and cognitive dynamics for studies in psychology, human-computer interaction, and behavioral science.
Rooted in over two decades of innovation from Nemesysco, Emotion-Logic leverages its Layered Voice Analysis (LVA) technology to go beyond words, uncovering the subtle emotional and cognitive dimensions of human communication. The result is a platform that transforms digital interactions into meaningful, emotionally resonant experiences.
Analyze Now: Emotion-Logic SaaS Services and Developer APIs
The Emotion-Logic platform bridges the gap between Genuine Emotion Analysis tools for businesses and powerful APIs for developers. Whether you need ready-to-use solutions for immediate insights or tools to build customized applications, our platform delivers.
SaaS Services: Empower Your Business with Emotion Insights
Our Analyze Now services are designed for businesses seeking actionable insights from voice data without requiring technical expertise. These tools integrate Layered Voice Analysis (LVA), Speech-to-Text (S2T), and Generative AI to unlock a deeper understanding of emotions, mood, and cognitive states.
1. FeelGPT
FeelGPT analyzes pre-recorded files, acting as a virtual expert powered by LVA. It provides:
- Emotional and cognitive insights from conversations.
- Mood, honesty, and personality assessments.
- Advanced analysis tailored to specific use cases, such as sales calls, customer interactions, and compliance reviews.
2. AppTone
AppTone sends questionnaires to targeted participants, enabling them to respond by voice. The platform analyzes their responses for:
- Honesty and risk levels.
- Mood and personality traits.
- Specific emotional reactions to key topics or questions, ideal for market research, compliance, and fraud detection.
3. Emotional Diamond Video Maker
This service overlays the Emotional Diamond analysis onto audio or video input, generating a dynamic video and report that showcases:
- Emotional and cognitive balance across key metrics.
- Points of risk or emotional spikes detected.
A downloadable video for presentations, training, or storytelling.
APIs: Build Your Own Emotion-Aware Applications
For developers, the Emotion-Logic APIs provide the flexibility to integrate emotional intelligence into your software and hardware solutions.
Key Features:
- Pre-Recorded File Analysis: Upload files and retrieve emotional and cognitive insights.
- Questionnaire Processing: Handle structured multi-file responses with ease.
- Streaming Analysis: Enable real-time emotion detection for live interactions or voice-controlled devices.
With comprehensive documentation, support for Docker self-hosting, and scalable cloud options, the APIs empower developers to create innovative solutions tailored to their needs.
Why Choose Emotion-Logic?
For Businesses:
- Instant access to emotion insights with Analyze Now tools.
- Actionable data for decision-making, customer engagement, and compliance.
- User-friendly interfaces requiring no technical expertise.
For Developers:
- Flexible APIs for building custom solutions.
- Self-hosted and cloud deployment options.
- Comprehensive documentation and developer support.
For Enterprises:
- SoC2 compliant, secure, and scalable for high-demand applications.
- Designed to meet the needs of industries including sales, customer service, healthcare, media, and compliance.
By combining the simplicity of SaaS tools with the power of developer APIs, Emotion-Logic helps businesses and developers unlock the true potential of emotion-aware technology. Let’s create the future of emotional intelligence together!
About Layered Voice Analysis (LVA™)
Layered Voice Analysis, or LVA, is a technology that provides a unique analysis of human voices.
This technology can detect a full range of genuine emotions, such as stress, sadness, joy, anger, discomfort, and embarrassment - and many more emotional/cognitive states that the speaker may not express outwardly using words and/or expressed intonation.
What sets LVA apart from other voice analysis technologies is its ability to go deep into the inaudible and uncontrollable properties of the voice and reveal emotional elements that are not expressed vocally while speaking.
This exceptional approach allows the technology to remain unbiased and free from the influence of cultural, gender, age, or language factors.
LVA has served cooperations and security entities for over 25 years and is research-backed and market-proven.
It can be used for various applications, ranging between fintech, insurance, and fraud detection, call center monitoring and real-time guidance, employee recruitment and assessments, bots and smart assistants, psycho-medical evaluations, investigations, and more.
With LVA, organizations can gain valuable insights to help make better decisions, save resources, and prevent misunderstanding.
It can also contribute to making the world safer by determining the motivation behind words used in high-risk security or forensic investigations.
Overall, LVA technology provides a unique knowledge that allows you to analyze reality, protect your businesses and customers, manage risks efficiently, and save resources.
LVA Concepts
This documentation page provides an overview of the key concepts and components of the Emotion Logic hub's Language and Voice Analysis (LVA) system. The LVA system is designed to analyze the deeper layers of the voice, ignoring the text and expressed emotions. It looks only at the uncontrolled layers of the voice where genuine emotions reside, making it useful for applications in customer support, sales, mental health monitoring, and human-machine interactions.
Table of Contents
- Bio-Markers Extraction
- Objective Emotions
- Calibration and Subjective Measurements
- Risk Formulas
- Integration and Use Cases
Bio-Markers Extraction
The initial process in the LVA system involves capturing 151 bio-markers from voice data. These biomarkers are generally divided into five main groups:
- Stress
- Energy
- Emotional
- Logical
- Mental states (including longer reactions that are more stable by definition, such as embarrassment, concentration, uneasiness, arousal)
Objective Emotions
After extracting the bio-markers, the LVA system calculates "Objective emotions." These emotions are called "Objective" because they are compared to the general public's emotional states. Objective emotions are scaled from 0 to 30, providing a quantitative representation of the individual's emotional state.
Calibration and Subjective Measurements
Next, a calibration process is performed to detect the normal ranges of the bio-markers for the current speaker, at that specifc time. Deviations from this baseline are then used to calculate "Subjective measurements." These measurements range from 30% to 300%, as they describe the current voice sample's changes from the baseline (100%).
Risk Formulas
In some applications of LVA, risk formulas will be employed to assess how extreme and unique the current emotional response is. This helps determine the level of honesty risk that should be assumed for a given statement. Different methods are used for evaluating the risk, depending on the application and context.
Integration and Use Cases
The LVA system can be integrated into various applications and industries, including:
- Customer support - to gauge customer satisfaction and tailor support interactions
- Sales - to identify customer needs and sentiments during sales calls
- Human resources (HR) - to evaluate job candidates during interviews, providing insights into their emotional states, stress levels, and authenticity, thus aiding in the selection of suitable candidates and improving the hiring process
- Mental health monitoring - to track emotional states and provide data for mental health professionals
- Human-machine interactions - to improve the naturalness and effectiveness of communication with AI systems
- Fraud detection - to assess the honesty risk in phone conversations or recorded messages, assisting organizations in detecting fraudulent activities and protecting their assets
- Human resources (HR) - to evaluate job candidates during interviews, providing insights into their emotional states, stress levels, and authenticity, thus aiding in the selection of suitable candidates and improving the hiring process
Emotional styles
Repeating emotional indicators around specific topics were found to reveal emotional styles and behavioral tendencies that can deliver meaningful insights about the speaker.
We have found correlations between the poles of the Emotional Diamond and several types of commonly used personality assessment systems around the BIG5 classifications.
Below are the identified correlations in the Emotional Diamond poles:
Emotional style: Energetic-Logical (EN-LO)
Characteristics: Fast-paced and outspoken, focused, and confident.
Emotional style: Energetic-Emotional (EN-EM)
Characteristics: Innovator, passionate leader, a people person.
Emotional style: Stressful-Emotional (ST-EM)
Characteristics: Accepting and warm, cautious and defensive at times.
Emotional style: Stressful-Logical (ST-LO)
Characteristics: Confident and logic-driven, intensive thinker, and protective.
LVA theory and types of lies
The LVA theory recognizes 6 types of lies differing one from the other by the motivation behind them and the emotional states that accompany the situation:
- Offensive lies – Lies made to gain profit/advantage that would otherwise not be received.
- Defensive lies – Lies told to protect the liar from harm, normally in stressful situations, for example when confronting the authorities.
- “White lies” – An intentional lie, with no intention to harm - or no harmful consequences, nor self-jeopardy to the liar.
- “Embarrassment lies” – Told to avoid temporary embarrassment, normally with no long-term effect.
- “Convenience lies” - Told to simplify a more complicated truth and are normally told with the intention to ease the description of the situation.
- Jokes – an untruth, told to entertain, with no jeopardy or consequences attached.
The “Deception Patterns”
Description
The Deception Patterns are 9 known emotional structures associated with different deceptive motivations that typically have a higher probability of containing deception.
The Deception Patterns are used for deeper analysis in the Offline Mode.
Using the Deception Patterns requires a good understanding of the situation in which the test is taken, as some deception patterns only apply to certain situations.
The following list explains the various Deception Patterns and the meanings associated with each of them:
Global Deception Patterns
Global deception patterns (Deception analysis without a 'Pn' symbol) reflect a situation in which two algorithms detected a statistically high probability of a lie, coupled with extreme lie stress.
This default deception pattern is LVA7’s basic deception detection engine, as such, it is always active, regardless of mode or user’s preferences.
Deception Pattern # 1 – “Offensive lies”
This pattern indicates a psychological condition in which extreme tension and concentration are present.
treat this pattern as a high risk of deception when talking to a subject who might be an offensive liar for determining a subject's involvement or knowledge about a particular issue.
This deception pattern can also be used when the subject feels that they are not in jeopardy.
When using the P.O.T. (explain)Investigation technique this is likely to be the case that indicates deception together with the “high anticipation” analysis.
Deception Pattern # 2 – “Deceptive Circuit” lies
A psychological condition in which extreme logical conflict and excitement indicate a probable deception.
Treat this pattern as a high risk of deception in a non-scripted conversation, in which a subject is feeling abnormal levels of excitement and extreme logical or cognitive stress.
Deception Pattern # 3 – “Extreme fear” lies
A psychological condition in which extreme levels of stress and high SOS ("Say or Stop") are present.
Treat this pattern as a high risk of deception only for direct responses such as - "No, I did not take the bag."
If you detect deception using this pattern, this is a serious warning of the general integrity of the tested party.
Deception Pattern # 4 – “Embarrassment lies”
Pay attention to this indication only if you feel the subject is not expected to feel embarrassed by the nature of the conversation.
Usually, it applies to non-scripted conversations.
Differentiate between the relevant issues when using this pattern to gauge situations with a high risk of deception.
When deception is detected around irrelevant topics, this is likely an indication that the speaker does not wish to talk about something or is embarrassed, in which case the deception indication should be ignored.
In relevant cases, try to understand whether the feeling of embarrassment is comprehensible for this specific question or sentence.
Because of its dual implication, Pattern # 4 is considered less reliable than the others.
Deception Pattern # 5 – “Focus point” lies
This pattern indicates a structure of extreme alertness and low thinking levels.
With this pattern too, it is important to differentiate between relevant, or hot issues and cold, or non-relevant ones.
If Deception Pattern # 5 was found in a relevant segment, this is likely an indication of deception.
However, if this deception pattern is found in non-relevant segments, it may be an indication of sarcasm or a spontaneous response.
Treat this pattern as a high risk of deception only when interrogating a subject within a structured conversation or any time the subject knows this will be the topic or relevant question.
This pattern should not be used for a non-scripted conversation.
Deception Pattern # 6 – “SOS lies”
This pattern indicates extremely low alertness and severe conflict about whether to “Say-Or-Stop” (S.O.S.).
If you receive an indication of this pattern, it is recommended that you continue investigating this issue in a non-scripted conversation in the Online Mode.
In a relevant issue, you may want to drill down into the related topic with the analyzed subject, as this could imply evasiveness on their part.
If you receive a warning of deception in an irrelevant top, it is up to you to decide whether to continue investigating this topic.
It may reveal an item the subject does not want to discuss.
It may, however, be an indication that there is a high level of background noise or a bad segment contained in the file.
It is recommended that you double-check these segments.
Deception Pattern # 7 – “Excitement-based lies”
This pattern indicates extremely low alertness and very high excitement.
This is an indication that the subject is not accustomed to lying or perhaps just doing it for "fun."
On the other hand, it might indicate a traumatic experience related to this issue.
Do not use this deception pattern when interrogating a subject about possible traumatic events.
Treat this pattern as a high risk of deception when interviewing a subject suspected to be an offensive liar, when offensive lies are suspected, or when using a Pick-of-Tension method for determining a subject's involvement or knowledge of a particular issue.
Moreover, this deception pattern can be effective even when the subject feels they are not in jeopardy.
Deception Pattern # 8 – “Self-criticism” lies
This pattern indicates extremely low alertness and very high conflict. The subject has a logical problem with their reply.
Do not use this pattern with a subject that may be extremely self-criticizing.
Repeated conflict about this specific issue may indicate a guilt complex. Here, it is important for you to decide whether you sense that the subject is confused. In case of a “justified” confusion, the P8 results should be ignored.
If the subject does not display any confusion, seems confident, expresses themselves clearly, and phrases things with ease, a P8 deception pattern will indicate a high probability of deception.
Deception Pattern # 9 – General extreme case
This pattern indicates extremely low alertness, high conflict, and excitement.
Treat this pattern as a high risk of deception when the subject appears as a normal, average person, i.e. when the other test parameters look fine.
The deception pattern itself is very similar to the Global Deception Pattern, and Deception Pattern # 9 is used as a backup for borderline cases.
Mental Effort Efficiency pair (MEE)
The MEE value, or Mental Effort Efficiency set of values describes 2 aspects of the mental effort (thinking) process over time, using more than a few segments:
The first index value is assessing the effort level as can be assumed from the average AVJ biomarker levels, and the other is how efficient the process is as can be assumed from the diversity (standard error rates) of the same AVJ biomarker over time.
For example, in both cases below the average AVJ level is almost the same, but the behavior of the parameter is very different, and we can assume the efficiency of the process on the left chart is much higher compared to the one on the right:

(In a way, that looks very similar to the CPU operation in your PC).
Interesting pairs of emotional responses
Out of the plurality of emotional readings LVA generates, comparing some values may add an additional level of understanding as to the emotional complexities and structures of the analyzed person.
Energy/Stress balance: Indicates aggressiveness Vs. one’s need to defend themselves.
Anticipation/Concentration: Indicates the level of desire to please the listener Vs. standing on his/her own principles.
Emotion/Logic: Indicated the level of rationality or impulsiveness of the analyzed person.
* Additional pairs may be added as the research develops.
Emotion Logic platform's basics
OK ! You Have an Account—What’s Next?
Once your account is created and your phone number validated, we’ll top it up with some free credits so you can experiment and develop at no cost. Your account operates on a prepaid model, and as your usage grows, it will be automatically upgraded with discounts based on activity levels.
You’re also assigned a default permission level that enables development for common use cases.
Emotion Logic: Two Main Entrances
Emotion Logic offers two main ways to access its services:
Analyze Now – A suite of ready-to-use tools requiring no setup. Simply choose a service and start working immediately.
Developers' Zone – For technology integrators building custom solutions with our APIs.
If you're only planning to use the Analyze Now services, select your service and start immediately. If you're a developer, continue reading to understand the basics of how to work with our APIs and seamlessly integrate our technology into your applications.
Two API Models: Choose Your Integration Path
Emotion Logic offers two distinct API models, depending on your use case and technical needs:
1. Regular API (Genuine Emotion Extraction API)
This API is designed for developers who only need to extract emotions from voice recordings that have already been processed into LVA datasets with no standard additions.
You handle: Speech-to-text, data preparation, AI, pre-processing before sending requests, and once data is received from Emotion Logic, build the storage, report, and displays.
We provide: Pure genuine emotion extraction based on your selected Layered Voice Analysis dataset.
Best for: Advanced users who already have a voice-processing pipeline and only need Emotion Logic’s core emotion analysis.
Integration: Uses a straightforward request-response model with standard API authentication.
2. "Analyze Now" API (Full End-to-End Analysis)
This API provides a complete voice analysis pipeline, handling speech-to-text, AI-based insights, and emotion detection in a single workflow.
You send: Raw audio files or initiation command.
We handle: Transcription, AI-powered insights, and emotion detection—all in one request.
Best for: Users who want an all-in-one solution without managing speech-to-text and pre-processing.
Integration: Requires a unique "API User" creation and follows a different authentication and request structure from the Regular API.
Key Difference: The Regular API is for emotion extraction from pre-processed datasets, while the Analyze Now API provides a turnkey solution that handles everything from raw audio to insights.
Funnel 1 - Create Your First Project (Regular API)
The architecture of the Regular API consists of Projects and Applications.
A Project represents a general type of use case (that may represent a general need and/or client), and an Application is a subset of the project that represents either a specific use of a dataset or an isolated endpoint (e.g., a remote Docker or a cloud user for a specific customer). This structure allows flexibility in managing external and internal deployments, enabling and disabling different installations without affecting others. Each Application in the "Regular API" scope has its own API key, usable across our cloud services or self-hosted Docker instances, and includes settings such as the number of seats in a call center site or expected usage levels.
When creating a new Project, the first Application is created automatically.
Step 1: Create a New Project
From the side menu, click the "Developer's Zone" button, then "Create a New Project". Give your new project a friendly name and click "Next". (You can create as many Projects and Applications as needed.)
Step 2: Choose an Application
Applications define the type of emotional analysis best suited to your use case.
The applications are sorted by the general use case they were designed for. Locate the dataset that best meets your needs and ensure that it provides the necessary outputs for your project. Each Application has its own output format, pricing model, and permissions.
When selecting an Application, you’ll see a detailed description & your pricing info. Once you’re satisfied, click "Choose this Application".
Step 3: Set the Specifics for This Endpoint/Docker
Set the number of seats you want your Docker deployment to support (if relevant) or the number of minutes you expect to consume daily, which will be charged from your credit upon use by the Docker. Please note that all cloud usage is simply charged per use and is not affected by Docker settings.
Once you are satisfied, click "Generate API Key", and a specific API key and password will be created. Keep these codes private, as they can be used to generate billing events in your account. Learn more about the standard APIs here.
Funnel 2 - Use the "Analyze Now" APIs
Using the "Analyze Now" APIs is a different process and requires the creation of an "API User".
Read the documentation available here to complete the process easily and effectively.
FeelGPT Advisors System
FeelGPT Overview:
Intelligent Analysis of Pre-Recorded Conversations and Emotions
FeelGPT is a virtual expert designed to bridge the gap between spoken words and true emotions. In fields such as fraud detection, customer service, and sales, understanding a speaker’s real feelings can lead to more informed decisions and improved outcomes. By combining advanced speech-to-text processing with genuine emotion detection through Layered Voice Analysis (LVA), FeelGPT provides deep insights that traditional analytics cannot.
Key Features
1. FeelGPT Advisors
FeelGPT offers specialized advisors tailored to various business needs:
- Fraud Detection: Identifies emotional indicators of dishonesty and risk, assisting in fraud investigations, particularly in insurance claims.
- Client Service Enhancement: Detects customer emotions in support calls, allowing service teams to proactively address dissatisfaction and improve engagement.
- Sales Optimization: Recognizes emotional signals of interest, hesitation, and resistance, helping sales teams refine their approach and close more deals.
- Additional Advisors: FeelGPT can be adapted for applications in mental health, market research, public speaking, and more.
2. Advanced Speech-to-Text Processing
FeelGPT transcribes entire conversations while preserving raw audio data, ensuring accurate emotional analysis.
3. Genuine Emotion Detection
Leveraging LVA, FeelGPT identifies subtle bio-markers in the voice that indicate emotions such as stress, confidence, hesitation, and uncertainty—often revealing insights beyond spoken words.
4. AI-Driven Cross-Referencing
FeelGPT correlates detected emotions with spoken content, identifying inconsistencies between verbal expression and emotional state. This enables decision-makers to uncover hidden sentiments and improve communication strategies.
5. Expert-Level Insights
Beyond raw data, FeelGPT delivers actionable intelligence tailored to industry-specific needs. It is used for:
- Compliance monitoring
- Customer experience enhancement
- Risk assessment in financial services
Benefits of FeelGPT
Enhanced Decision-Making
- Identifies discrepancies between spoken words and underlying emotions, reducing risk and improving decision accuracy.
- Aids fraud detection by revealing emotional inconsistencies.
Enhances customer support by flagging distress or dissatisfaction.
- Time Efficiency & Scalability
- Automates the analysis of large volumes of calls, eliminating the need for manual review.
- Enables real-time processing and insights, improving operational efficiency.
Versatility & Customization
- FeelGPT Advisors are fine-tuned for different use cases, ensuring relevance across industries.
- The system can be adapted for evolving business needs.
How to Use FeelGPT
- In the Emotion Logic platform, after logging in, select "Analyze Now" from the left-side menu.
- Select the FeelGPT advisor designed for your specific needs. FeelGPTs can be customized for any use case.
- Upload Pre-Recorded Audio: FeelGPT processes existing call recordings.
- Speech-to-Text Conversion: The system transcribes the conversation while maintaining audio integrity.
- Emotion Analysis: LVA technology extracts emotional markers from voice patterns.
- AI Interpretation: The detected emotions are cross-referenced with spoken words.
- Insight Generation: Actionable intelligence is provided in a structured report.
Getting Started
To explore the full range of FeelGPT Advisors and begin analyzing conversations for actionable insights, visit EMLO’s FeelGPT page.
Annex 1 : The FeelGPT protocol example - The merger of transcript and emotions that makes the FeelGPT work.

FeelGPT Field: An Overview
Definition:
Designed for developers using Emotion Logic APIs, the FeelGPT field is a JSON output parameter that provides a textual representation of detected emotions, sometimes including intensity levels. This field enables seamless integration of emotion insights into applications, supporting automated responses and data-driven analysis.
Format:
The FeelGPT field typically presents data in the following format:
[emotion:intensity;emotion:intensity, ...]
For instance:
[passionate:1; hesitant:4]
or
[confused:2]
It may also include indicators about the autheticity of the speaker, specifically highlighting when the speaker may be inaccurate or dishonest.
Applications:
While the primary purpose of the FeelGPT field is to offer insights into the speaker's emotions, it can also be integrated into systems like ChatGPT to provide more contextually relevant responses. Such systems can utilize the emotional data to adjust the verbosity, tone, and content of their output, ensuring more meaningful interactions.
Development Status:
It's important to note that the FeelGPT field is still under active development. As such, users should be aware that:
- The exact textual representation of emotions may evolve over time.
- There might not always be a direct textual match between consecutive versions of the system.
- For those integrating FeelGPT into their systems, it's recommended to focus on the broader emotional context rather than seeking exact textual matches. This approach will ensure a more resilient and adaptable system, especially as the FeelGPT field continues to mature.
AppTone Questionnaires System
AppTone: Genuine Emotion Analysis for Voice-Based Questionnaires and Audio Responses
Overview
AppTone is one of the "Analyze Now" services that analyzes spoken responses in voice-based questionnaires to provide insights into emotional and psychological states using Layered Voice Analysis (LVA) technology. It is uniquely integrated with WhatsApp (and potentially other voice-enabled chat services) to collect audio responses from users, making it a flexible tool for various applications, including fraud detection, compliance monitoring, customer service, and psychological assessments.
Key Features
1. Advanced Emotion Detection
AppTone utilizes specialized "questionnaire ready" datasets within LVA technology to adapt to various use cases, allowing for the detection of a wide range of emotions such as stress, anxiety, confidence, and uncertainty. Additionally, it evaluates honesty levels and risk factors using professionally calibrated datasets. Note that not all datasets include risk indicators; only certain professional-level datasets provide this capability.
Emotional analysis is independent of spoken content, focusing solely on voice characteristics, and is available for any language without requiring additional tuning.
2. Post-Session Automated Reports
AppTone collects responses via WhatsApp and processes them efficiently to generate automated reports at the end of each session, offering comprehensive emotional insights based on user responses.
3. Fraud Detection
Identifies signs of dishonesty or stress, helping detect potential fraud.
Used in financial transactions, insurance claims, and other high-risk interactions.
4. Customer Feedback and Survey Analysis
AppTone is optimized for post-call surveys and customer feedback collection, enabling businesses to gather meaningful insights through structured voice-based questionnaires.
It can be used to launch specialized tests via QR codes, allowing Emotion Logic's clients to gather emotional insights from their customers.
Helps businesses assess overall sentiment and improve customer experience based on structured feedback.
5. Compliance Monitoring
Organizations can use AppTone to deploy compliance-related questionnaires via WhatsApp or web-based surveys, allowing employees or clients to respond using voice recordings.
The collected responses are analyzed for emotional markers and risk indicators, helping companies identify areas of concern and ensure compliance with industry regulations.
6. Psychological and Psychiatric Applications
AppTone enables the collection and analysis of voice responses to aid mental health assessments.
Assists clinicians in evaluating emotional states and tracking patient progress over time.
7. Personalized Feedback and Training
Provides detailed feedback on communication skills and emotional intelligence.
Helps individuals refine their speaking style for professional and personal development.
Customizable Questionnaires
- AppTone questionnaires can be fully customized to meet diverse needs. Users can create their own questionnaires or use pre-designed templates, enabling deployment in less than five minutes.
- Questions should be framed to encourage longer responses and storytelling rather than simple yes/no answers. This allows for richer audio data collection, leading to more accurate emotional analysis.
How to Send a Questionnaire
To manually send a questionnaire to any party of interest:
- Log into the platform and from the left side menu select "Analyze Now" and "AppTone"
- Select the test you want to send, and copy it to your personal Gallery.
- Click the send button and enter your target person's details and an optional email if you want the report to be sent to an email.
- Click send again on this screen to complete the task.
QR Code Activation: Businesses can generate QR codes linked to specific questionnaires. When scanned, these QR codes initiate the test from the scanner's phone, making it easy forcustomers or employees to participate in evaluations instantly.
Customization and Deployment: Users can create their own questionnaires or select from pre-designed templates, enabling distribution in less than five minutes. To enhance analysis, questions should be structured to encourage detailed responses rather than simple yes/no answers, ensuring richer voice data collection.
How AppTone Works for the receiver:
Initiate a Session
- Testees receive a questionnaire via WhatsApp, a web interface or another voice-enabled chat service.
- They respond by recording and submitting their answers.
Speech-to-Emotion Analysis
- AppTone transcribes the responses while preserving voice data for emotional analysis.
- LVA detects emotional markers in the voice, assessing stress, confidence, hesitation, and other psychological cues.
AI-Driven Cross-Referencing
- Emotions detected in the voice are cross-referenced with verbal content.
- This helps identify discrepancies between what was said and how it was emotionally conveyed.
Automated Report Generation
- At the end of the session, a structured report is generated with emotional and risk insights.
- The report includes key findings relevant to fraud risk, compliance, customer sentiment, or mental health evaluation.
Use Case Examples
- Fraud Prevention: Detects emotional inconsistencies in insurance claims and financial transactions and pin-points relevant high risk topics and answers.
- Customer Sentiment Analysis: Helps businesses measure customer satisfaction and identify concerns.
- HR and Recruitment: Assesses candidates' emotional responses in interview settings for true personality assessment, Core-Values-Competencies evaluation, as well as risk indications around topics relevant for the company's protection .
- Mental Health Monitoring: Supports therapists in tracking emotional health trends over time.
Getting Started
To integrate AppTone into your workflow or explore its capabilities, visit EMLO’s AppTone page.
AppTone
Connecting emotions, voice, and data, providing insightful analysis independent of tonality, language, or cultural context.
AppTone uses WhatsApp to send questionnaires for a range of purposes, such as market research, insurance fraud detection, credit risk assessment, and many more. AppTone uses cutting-edge technologies to gather voice answers, analyze them, and produce extensive automated reports.
Introduction
What is Apptone?
Apptone analyzes customer emotions through voice responses to questionnaires sent via messaging apps. It provides a thorough and effective way to record, transcribe, analyze, and derive insights from spoken content. Depending on the assessed field, a set of questions — a questionnaire — is sent to the applicant via messenger. The applicant records the answers, and the AppTone analyzes the voice recordings and generates the report, with all the key points evaluated and flagged if any issues are detected.
AppTone provides:
- Ease of Use
Customers enjoy a straightforward and personal way to communicate their feedback, using their own voice through familiar messaging platforms, making the process fast and user-friendly.
- Rapid Insights
AppTone enables businesses to quickly process and analyze voice data, turning customer emotions into actionable insights with unprecedented speed.
- Personalized Customer Experience
By understanding the nuances of customer emotions, companies can offer highly personalized responses and services, deepening customer engagement and satisfaction.
How It Works
First step
You initiate the process by choosing the right questionnaire, either a preset or a custom one, made on your own.
Questionnaire dispatch
AppTone sends a tailored voice questionnaire directly to the applicant's phone via a popular messaging app. This makes it possible for candidates to record their responses in a comfortable and relaxed setting.


Fig. 1: Example of a Questionnaire Sent to the Recipient
Response recording
The applicants record the answers to the questionnaire whenever it is most convenient for them, preferably in a quiet, peaceful environment.
Instant analysis
Following submission of the responses, the recordings are processed instantly by AppTone, which looks for fraud and risk indicators.
The analysis is powered by Layered Voice Analysis (LVA), a technology that enables the detection of human emotions and personalities for risk-assessment calculations.
More on Layered Voice Analysis (LVA) Technology.
Reporting
A detailed report with decision-making information related to the chosen area is generated and delivered to the customer within seconds. This report includes actionable insights, enabling quick and informed decision-making.
The analysis is conducted irrespective of language or tone, and you can even use ChatGPT Analysis to get more AI insights.
Through the analysis of voice recordings from any relevant parties, Apptone is able to identify subtle signs of dishonesty, including, but not limited to:
- Changes in Vocal Stress: Individuals who fabricate information or feel uncomfortable with deception may exhibit changes in vocal stress levels.
- Inconsistencies in Emotional Responses: The technology can identify discrepancies between the emotions expressed in the voice and the situation described, potentially revealing attempts to exaggerate or feign symptoms.
- Linguistic Markers of Deception: Certain word choices, sentence structures, and hesitation patterns can indicate attempts to mislead.
AppTone Advantages
- Ease of Use for Customers: Through recognizable messaging platforms, customers have a simple and intimate means of providing feedback in their own voice, which expedites and simplifies the process.
- Quick Insights for Businesses: AppTone helps companies process and analyze voice data fast, converting client emotions into actionable insights with unprecedented speed.
- Personalized Customer Experience: Businesses can increase customer engagement and satisfaction by providing highly tailored responses and services by comprehending the subtleties of customers' emotions.
What do We Get out of the Result?
Depending on the specific Questionnaire chosen or created by the customer, after Apptone completes the analysis, the customer receives a detailed Report, with all the key points evaluated and flagged if any issues are detected.
If we take a Candidate Insight Questionnaire as an example, the Report will contain:
- Test Conclusion, which provides you with information about the transcription, AI insights, and emotional analysis by summarizing the reporting results.

Fig. 2: Extract from the Report: Test Conclusion
- The Personality Core Type of a candidate and Emotional Diamond Analysis.
There are four Personality Core Types:
1. Energetic Logical
Characterized by directness, decisiveness, and dominance, this style prefers leadership over followership. Individuals with this style seek management positions, exhibiting high self-confidence with minimal fear of consequences. Energetic and mission-focused, they are logical-driven risk-takers who passionately defend their beliefs and engage in arguments when disagreements arise.
2. Energetic Emotional
Thriving in the spotlight, this style enjoys being the center of attention. Individuals are enthusiastic, optimistic, and emotionally expressive. They place trust in others, enjoy teamwork, and possess natural creativity. While they can be impulsive, they excel at problem-solving and thinking outside the box. This personality type tends to encourage and motivate, preferring to avoid and negotiate conflicts. However, they may sometimes display recklessness, excessive optimism, daydreaming, and emotional instability.
3. Stressed Emotional
Known for stability and predictability, this style is friendly, sympathetic, and generous in relationships. A good listener, they value close personal connections, though they can be possessive. Suspecting strangers, they easily feel uncomfortable. Striving for consensus, they address conflicts as they arise, displaying compliance towards authority. Under high stress, they exhibit careful behavior, avoiding conflicts even at the cost of giving up more than necessary.
4. Stressed Logical
Precise, detail-oriented, and intensive thinkers, this style excels in analysis and systematic decision-making. They make well-informed decisions after thorough research and consideration. Risk-averse, they focus on details and problem-solving, making them creative thinkers. When faced with proposals, individuals with this style meticulously think through every aspect, offering realistic estimates and voicing concerns. While excellent in research, analysis, or information testing, their careful and complex thinking processes may pose challenges in leading and inspiring others with passion.
The Emotional Diamond Analysis is a visual representation of emotional states and their respective intensities.

Fig. 2.1: Extract from the Report: Personality Core Type and Emotional Diamond Analysis
Risk Assessment according to specific topics, with highlights of the risk points.

Fig. 2.2: Extract from the Report
And Full Report with details on each topic and question, with the possibility to listen to the respondent’s answers.

Fig. 2.3: Extract from the Full Report
Please refer to the Report Types article for more detailed information on the analysis results.
Getting Started
The process of using AppTone is simple, very user-friendly, and consists of several steps. All you have to do is to:
Once the recipient is done with the answers, the system performs the analysis and generates a report with all the details on the assessed parameters and indicators.
Select the Questionnaire
A Questionnaire is a set of questions that are sent to the recipient for further analysis.
You can use a Template (please see the details below) or create a new Questionnaire (please refer to the article Create New Questionnaire).
Use Template
1. Go to Analyze Now > Apptone > Questionnaires Management.

Fig.1: Questionnaires Management Screen
- Templates tab contains the list of Templates which can be further used.
- My Questionnaires tab contains the questionnaires, owned by a user (copied from Templates or created previously).
Note: Sending and editing the Questionnaires is available for My Questionnaires only.
2. Go to Templates tab and select Copy to My Questionnaires button on the needed Questionnaire card.
Once a template has been added to My Questionnaires it can be edited, deleted and sent to the end-user.
Use the filter to sort the Questionnaires by language or category.
Clicking on any place on the card will open the full Questionnaire details. To return to the Questionnaires selection, select Back.
Send the Questionnaire
To one recipient
1. Go to My Questionnaires and select Send on the Questionnaire card to send it right away.
You can select Edit icon to edit the Questionnaire before sending, if needed.

Fig.2: Questionnaire Card
2. Fill in the form:
- Recipient name and phone number.
- Identifier – Create an identifier for this questionnaire. It can be any word or number combination.
- Email for Report to be sent to.
Price details will also be displayed in the form.
3. Select Send.

Fig.3: Send to Customer Pop-up
To multiple recipients
1. Go to My Questionnaires and select Send on the Questionnaire card.
You can select Edit icon to edit the Questionnaire before sending, if needed.
2.Select Upload Your Own List.

3. Download a CSV template and fill in the recipients' details there according to the example that will be inside the file.
4. Upload the list.
The recipients's details can be edited.

Fig 4: Send to Customer - Upload List
3. Select Send to send the questionnaire to the indicated recipients.
The price summarizes all the questionnaires that will be sent.
Get the Report
Once the Questionnaire is sent to the end user, the information on it will appear in the Reports Tab, where you can see the status of the Questionnaire and see the detailed report.
Please refer to the Report Types article to get more information about what the report consists of.
Questionnaires Management Tab
Questionnaires Management Tab allows the user to view and manage questionnaires.
Analyze Now > AppTone > Questionnaires Management will lead you to all the questionnaires available.
- Templates: can not be edited, they can only be viewed and Copied to My Questionnaires.
- My Questionnaires: can be edited, deleted/archived, and sent to customers.
Fig.1: Questionnaire Management screen
Use the Filter to sort the Questionnaires by Language (multiple languages can be selected) or Category.
Click on any place on the card will open the Questionnaire details. To return to the Questionnaires selection select Back.

Fig.2 Questionnaire Details
On the Questionnaires Management tab it is possible to perform the following actions:
- Send Questionnaires to customers
Please, see How to Send Questionnaire for more details.
- Create New Questionnaires
Please, see How to Create New Questionnaire for more details.
- Edit the existing Questionnaires
Please, see How to Edit Questionnaire for more details.
Create New Questionnaire
Please note that creating a new Questionnaire is available for the desktop version only.
To create a new Questionnaire:
- Go to Analyze Now > Apptone, and select Add New.

Fig. 1: Add New Questionnaire Button
There will be three tabs to fill in:

Fig. 2: Create New Questionnaire Tabs
2. Fill in the fields in all three tabs. The required fields are marked with a red dot.
3. Select Create.
A new Questionnaire is now created and can be managed in the Questionnaire Management Tab in Analyze Now > Apptone.
General Tab
This tab consists of general questionnaire configuration settings.

Fig. 3: General Settings of the Questionnaire
- Questionnaire Name – Enter the name for the Questionnaire.
- Language – Select the language of the questions.
- Category – Select a category from the list or enter a new one. Multiple categories can be selected. Adding new categories is available for users with admin rights only.
- Tags – Add tags to the questionnaire for the search. Multiple tags can be entered.
- Description – Enter the description of a new Questionnaire in a free form. This text will be shown on the AppTone home page.
- Card Image – Add a picture for the Questionnaire description that will appear on the Apptone homepage. If no picture is added, a default placeholder will be used.
- Plug Type - Select from a drop-down a plug type. It defines a set of data that will be available in the report according to a specific use case:
- AppTone – Risk Assessment
- AppTone – Human Resources
- AppTone – Personality test – FUN
- AppTone – Well-being
- Price per questionnaire – This field is filled automatically after selecting the plug type. That is how much sending one questionnaire will cost.
- Activation Code (TBC) – If a questionnaire is on public stock, a customer cannot send a code.
- Advertisement Link (TBC).
- Report options – Select which items to include in the Report:
- Show Profiles
- Show Tags
- Show Transcription
- Show Emotional Diamond
- Show Emotion Player
- Show Image
- Main Risk Indicator. This selection determines which risk parameter is used to calculate the risk score per topic.
- Use Objective Risk
- Use Subjective Risk
- Use Final Risk
- Report Delivery Options – Select how the Report will be delivered:
- Send report to email – The .pdf report will be sent to the email specified in the step when the recipient’s details are filled in before sending the Questionnaire.
- Send report in Chat – The .pdf report will be sent in the WhatsApp Chat.
Once all the required fields are filled, the red dot near the tab name will disappear.
Topics & Questions Tab
This tab consists of the configuration relating to the questions sent to the recipient.
Translating options

Fig 4: Translation Settings of the Questionnaire
You can choose one of the supported languages from a drop-down list and automatically translate the questionnaire.
Select + to add a language. Once selected, the new translation will appear. The fields Retry message, Closing message, and Topics and Questions will be translated to the language chosen. You can edit and change the text if needed.

Fig. 5: Topics & Questions Settings of the Questionnaire
- Introduction Message – Select from a drop-down list the opening message the user will receive as an introduction.
- Closing Message – Enter the text in the free form for the last message the user will receive as the last message after completing the questionnaire.
- Retry Message – Select from a drop-down a message the user will receive in case the recording has failed.
- Cancellation (Pull back) Message – Select from a drop-down list a message the user will receive in case there is a need to pull back a sent questionnaire.
- Use Reminder – Use a toggle to turn on the reminder for a user. In cases where the invitation has been sent and the customer hasn’t replied yet, an automatic reminder will be sent.
- Reminder Frequency – Select the frequency of the reminders from a drop-down list.
- Reminder Message – Select from a drop-down list the message that will be sent to a user when reminding them to answer the questions.
Questions table
- Topic column – Enter the topic name for the corresponding question. The questions will be grouped according to topics in the Report.
- Question – Enter the question text in this column.
- Media – Select Add Media to add one or more images, audio, or video files to a questionnaire.
- Type/Relevancy – Select from a drop-down list the option for how this question will be processed and analyzed:
- Personality - These questions aim to assess the respondent's core strengths, weaknesses, and unique personality traits. Responses help identify consistent behavioral patterns and underlying personality characteristics.
- Personality + Risk - This combined category evaluates both personality traits and potential risk factors. It offers insights into the respondent's personality while also assessing their susceptibility to risk, using a dual perspective on personality and risk elements
- Risk - Background - These are broad, introductory questions designed to introduce the topic and ease the respondent into the subject matter. They help set the mental context for the upcoming questions and facilitate a smoother transition between topics.
- Risk - 3rd Party Knowledge - These questions assess the respondent's knowledge of potential third-party involvement, helping to clear any tension related to external knowledge of risky behaviors. This allows for a more accurate focus on the respondent's personal involvement.
- Risk - Secondary involvement - This type focuses on the respondent's indirect or past involvement in risky situations, typically spanning the last five years. It aims to gauge any historical connection to risk-related behavior.
- Risk - Primary Involvement - The most relevant questions in terms of risk assessment, these focus on recent and direct personal involvement in risk-related activities, ideally within the past year. They are designed to detect high-relevancy responses and are central to assessing immediate risk potential.
GPT Instructions Tab
This tab settings allow you to turn on/off the usage of ChatGPT Analysis and generate the explanation to the conclusion made by AI according to the answers provided.

Fig. 6: Extract from the Report when ChatGPT Analysis is Enabled
Use a toggle to Enable ChatGPT Analysis.

Fig. 7: ChatGPT Settings of the Questionnaire
- Report Instructions (ChatGPT) – Enter the instructions for ChatGPT.
Example for Report Instructions (ChatGPT):
Hi chat, your task is to analyze a test transcript for fraud. The transcript includes answers given to an insurance questionnaire by a claimant, together with their genuine emotions and some indications about their honesty reading marked in square brackets. Begin your analysis by reading the entire transcript to understand the claimant's communication style, honesty level, and emotional expression. Understand the overall flow and context of the conversation. Pay special attention to any sections that are particularly intense, conflicted, or where the tone changes significantly. Emotion Analysis: Analyze the emotions encoded in "[]" in the transcript context. Catalog the emotions detected and the associated RISK indications to critical and relevant details of the claim. Note any patterns or anomalies. Contextual Assessment: Compare the observed emotions to what would be expected in such situations and note any deviations and repeating indications around the same issues. Inconsistency Check: Identify discrepancies between the spoken words and the encoded emotions and inconsistencies within the conversation, such as conflicting statements or stories that change over time. Fraud Risk Rating: Keep in mind some level of uncertainty and internal doubt may be expected in answers about locations, numbers, exact time, street names, third-party descriptions, and alike. Use the frequency and severity of risk and internal doubt indications as well as clear inconsistencies to assign a fraud risk rating on a scale of 1 to 5. Assign Risk level 1 to indicate minimal risk and 5 to indicate almost certain fraud. Summary and Hashtag Generation: Write a simple-to-understand summary of your analysis, highlighting key points that influenced your fraud risk rating. Generate a hashtag to represent the risk level using words instead of numbers: For level 1 or 2, use "#RISK-LEVEL-LOW" and tag it as @green for low risk. For level 3, use "#RISK-LEVEL-MID" and tag it as @yellow. For levels 4 or 5, use "#RISK-LEVEL-HIGH" and tag it as @red for high risk. Include specific examples from the transcript that support your assessment and the reasoning behind the chosen risk level and color indicator. Provide all your report in English, except for the color markers. Keep your report around 200 words.
- Temperature box – Free number, default 0 (floating between 0-2).
This parameter relates to the randomness of the generated text, i.e., the selection of words. Higher temperatures allow for more variation and randomness in the created text, while lower temperatures produce more conservative and predictable outputs.
- Report language – Select from a drop-down list the language for the ChatGPT report. Available languages
- Show title image – Use a toggle to show/hide the title image (the image in the report related to the GPT analysis). When a toggle is enabled, fill in the Image Description field.
- Image Description – Enter the description in a free form for the title image.
Once all the required fields are filled in, select Create to save the changes and to create a Questionnaire.
It will further be available in My Questionnaires in the Analyze Now > AppTone > Questionnaire Management Tab.
Edit Questionnaire
Please note: Only the Questionnaires in My Questionnaires section can be edited. Templates can be edited only after they are copied to My Questionnaires. In case the My Questionnaires section is empty, create a new Questionnaire or Copy a Questionnaire from Templates.
Questionnaires created by a user can be edited or changed without limitations, or deleted if required.
To Edit a Questionnaire
Go to Analyze Now > Apptone > Questionnaires Management > My Questionnaires and click the edit icon on the corresponding Questionnaire card.
To Edit a Template
1. Go to Analyze Now > Apptone > Questionnaires Management > Templates and Copy a Template to My Questionnairs selecting the corresponding button on the Questionnaire card.
2. Go to Analyze Now > Apptone > Questionnaires Management > My Questionnaires and click the edit icon on the corresponding Questionnaire card.
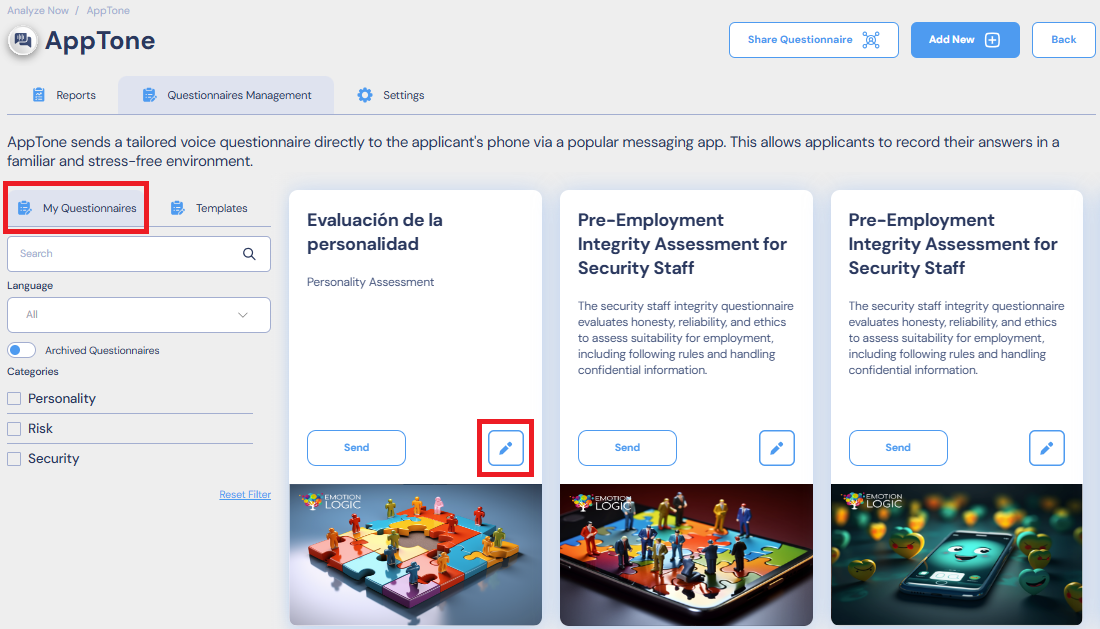
Fig. 1: Edit Questionnaire Button
The Questionnaire details will appear on the screen.

Fig. 2: Edit Questionnaire: General Tab
2. Edit the fields in three tabs according to your requirements and needs.
Please find the details on fields description by the following links:
3. Once the editing is done, select Save.
Now the Questionnaire is ready and can be sent to a customer.
See more about how to Send a Questionnaire.
Reports Tab
The Reports tab shows the overall statistics on the reports, as well as all the reports available. The page consists of three sections:
Display Filters

Fig. 1: Reports: Available Filtration Options
You can select which reports to display, applying the filters available:
- By recipient name (the name defined when sending the questionnaire to the recipient)
- By questionnaire name (defined when editing the questionnaire)
- By period of time (Last 7 days, Per month, Per year)
- By status:
- Pending – the recipient hasn’t completed the questionnaire yet.
- Running – the recipient is in the process of completing the questionnaire.
- Analyzing – the system is analyzing the recipient’s responses.
- Completed – the data analysis is completed.
- Cancelled – the questionnaire has been revoked and is cancelled.
All the filters are applied on the fly. Select Refresh to force the information display to update.
Note: The statistics graph and the reports table will display the information according to the filters applied.
Statistics Graph
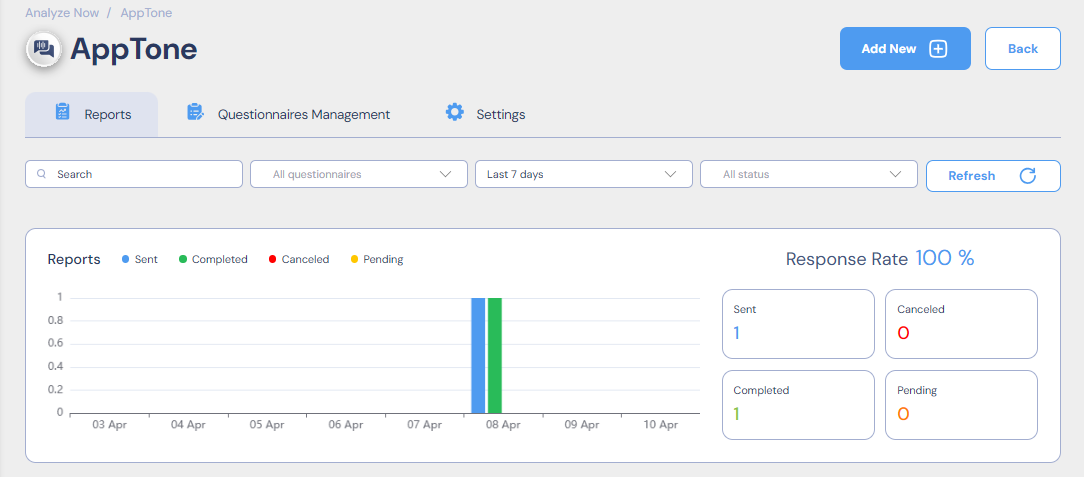
Fig. 2: Reports: Statistics Graph
The statistics graph is a bar chart, where:
- X-axis (horizontal) – period of time selected.
- Y-axis (vertical) – number of reports.
The bar color corresponds to the report status:
- Blue – Sent
- Green – Completed
- Red – Cancelled
- Yellow – Pending
The right part of the graph contains information on Response Rate (%), and the number of reports with a particular Status.
Reports Table
The Reports Table contains a list of all the reports according to the filters applied, with the following details:
- Name – Recipient name, entered in the step of sending the questionnaire.
- Questionnaire Name.
- Conclusion – General conclusion made after the analysis, depending on the report type.
- Phone Number of the recipient, to whom the questionnaire was sent.
- Identifier – Identification number of the recipient, entered in the step of sending the questionnaire.
- Status of the questionnaire and analysis.
- Create Date when a questionnaire was created.
- Start Date when a recipient started answering the questionnaire.
- End Date when a recipient finished answering the questionnaire.
- Completed Date when a recipient finished answering the questionnaire.
The Columns can be sorted by name (alphabetically ascending or descending) by clicking the icon ![]() .
.
Click on the Name to open the report for this recipient.
Click on the Questionnaire Name to open the Questionnaire details.

Fig. 3: Reports Table
Please refer to the Report Types article for more detailed information about what the Report consists of and how to read it.
Hover on the Report line to select from the possible actions, the icons will appear on the right:
- Download as a .pdf file.
- Delete the Report.

Fig. 4: Reports: Download and Delete Buttons
You can also select multiple Reports to download or delete; just tick the needed ones, or tick the first column to select all.

Fig. 5: Reports: Multiple Selection Options
To open the Report click on its name in the table. Please refer to the Report Types article for more detailed information about what the Report consists of.
Report Types
This article provides information on what each type of the report consists of.
Basically, there are three types of reports: Risk, Personality, and a mixed one: Personality + Risk. We will explain each section of the report one by one, giving you an overall understanding of how to read the outcoming result.
General Information
The data provided in the Report may vary and depends on the Questionnaire configuration, i.e., what report options were selected for the particular Questionnaire in the General Tab of the Questionnaires Management. These settings affect the way the report appears and what kind of report it is.
More on Questionnaire Configuration.

Fig. 1: Questionnaires Management: General Settings
Basically, there are three types of reports:
Please refer to the sections below to find the relevant information on each type of the Report.
Report Page
The upper section of the page refers to the report display and contains several tabs:
- Report tab shows this report.
- JSON tab shows the JSON response of this request in a built-in JSON viewer.
- Developers tab will show instructions and source code.
And download options:
- The download icons on the right let you download the report in the respective formats: JSON, PDF, and CSV.

Fig. 2: Report: Display and Download Options
All further information in the report is divided into sections, and is grouped accordingly. The sections are collapsed by default, which makes it easier to navigate.
The sections description is given below, according to the Report Type.
Risk Report
Risk assessment primary goal is to identify whether or not we detected potential risks in specific respondents replies to the Questionnaire.
The first section contains general information on the Report, such as:
- Report Name: name provided by the user to name the report.
- Test Type: the type of test as defined by the AppTone back office.
- Date when the Report was generated.
![]()
Fig. 3: Risk Report: General Risk Score
Test Conclusion
It shows the General Risk Score of the respondent.
Low Risk: Score: 5-40
No significant indications of risk were detected. If the provided information is logically and textually acceptable, no additional investigation is required.
Medium Risk: Score: 41-60
Review the questions that contributed to the elevated risk. It is advisable to conduct a follow-up interview to further explore the topic, focusing on more specific and detailed questions to clarify the underlying reasons for the increased risk.
High Risk: Score: 61-95
The applicant displayed extreme reactions to the questions within the specific topic. The provided information should be carefully reviewed and subjected to further investigation to address any concerns.

Fig. 4: Risk Report: General Risk Score
If the ChatGPT option was enabled (Questionnaires Management > GPT Instructions > Enable ChatGPT Analysis), this section will also contain the ChatGPT conclusion:

Fig. 5: Risk Report: ChatGPT Summary for Test Conclusion
Topic Risk Report
The Topic Risk Report aggregates all the topics and shows the risk indications for each one, as well as whether there is an indication of Withholding Information in the topic.

Fig. 6: Risk Report: Topic Risk Report Section
Risk Highlights
The Risk Highlights section shows the following highlights if they were detected:
- General: Withholding information, General Stress, Aggression, or Distress.
- Questions: Highlights of the detected risk points in the respective questions, marked accordingly:
- Red – High risk level.
- Yellow – medium risk level.
The Risk Highlights section can be copied.

Fig. 7: Risk Report: Risk Highlights Section
Full Report
The Full report section contains detailed analysis and risk indicators for each question answered.
The questions are grouped according to Questionnaire topics.
Each Topic and question can be collapsed.
Questionnaire Topics
This section displays:
- Topic Name – Set by the user in the Questionnaires Management > Topics & Questions Tab.
- Topic Risk – Risk indicator per topic.
- State of Mind – Indications of the respondent’s state per topic: Logical, Stress, Hesitation, Emotion Logic Balance, etc.
- All the Questions included in this topic.

Fig. 8: Risk Report: Topic Section
Question
The Question section contains the indicators for each question on the topic, with the following details:
- Question number – appears in green, orange, or red according to the risk value of the question, with a color-coded alert icon.
- Question text with Volume and Noise level icons next to it.
- Playback of the recording.
- Transcription of the audio reply, if available, with risk indications color-coded.
Note: If the question is masked as containing PII, the transcription will not be available.
- Risk Analysis section – shows the risk assessment per question, with:
- Question’s risk score and Indications relating to Sense of Risk, Inner Conflict, and Stress Level:
- Sense of Risk measures multiple emotional variables to assess the speaker's level of self-filtering and emotional guard.
High values suggest that the speaker strongly desires to avoid the subject or the situation, or feels at risk. - Inner Conflict focuses on acute risk indications that are compared to the speaker's emotional baseline.
High values suggest an inner conflict between what the speaker knows and what they are expressing verbally. - Stress refers to the general level of “danger” or negative expectation the subject felt when discussing the topic/question.
The higher the stress level is, the more sense of jeopardy the subject attaches to the topic at hand.
- Sense of Risk measures multiple emotional variables to assess the speaker's level of self-filtering and emotional guard.
- Question’s risk score and Indications relating to Sense of Risk, Inner Conflict, and Stress Level:
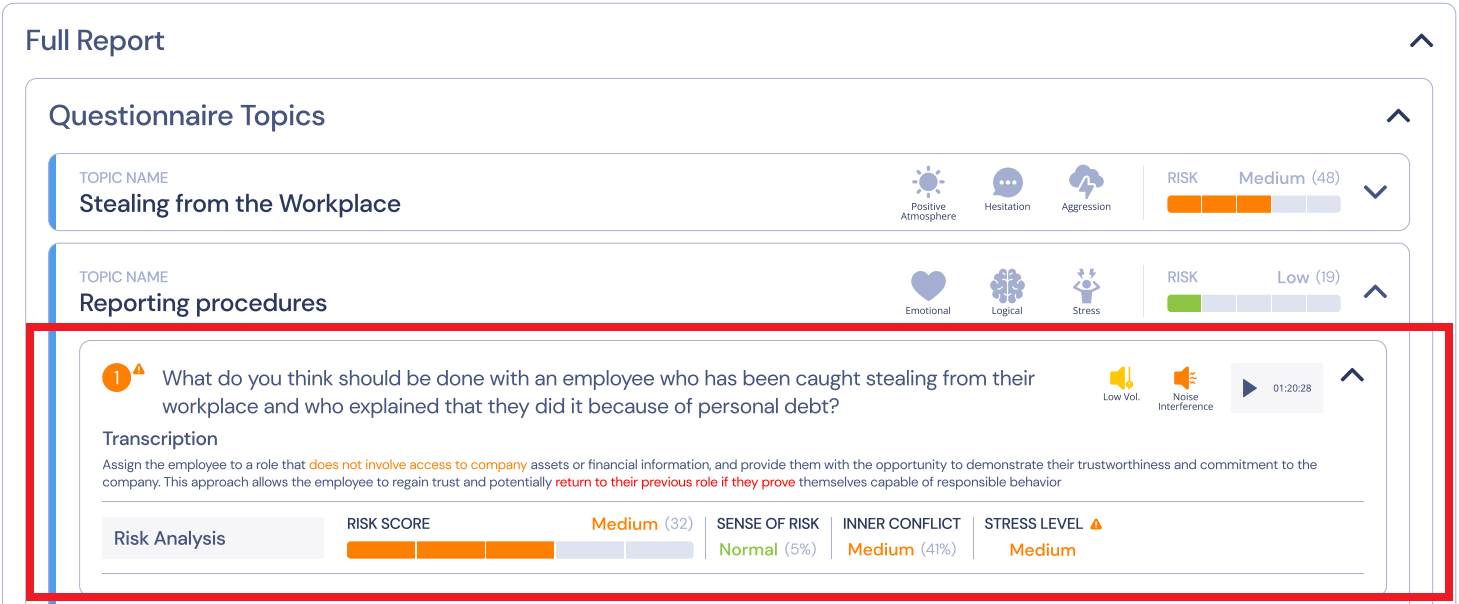
Fig. 9: Risk Report: Question Section
Profiles
This section shows the indicators of Emotions profiles and the state of a respondent for each of them.
Stress Profile
CLStress Score – Summarizes general stress level behavior and indicates the recovery ability from acute stress spikes.
Stress – Indicates how nervous or concerned the speaker is. Note that spikes of stress are common.
Extreme Stress Counters – Extreme stress counters track the number of extreme stress segments and consecutive stress portions detected in the call.
Mood Profile
Evaluation of mood detected. Percentage of Joy, Sadness, and Aggression.
Behavioral Profile
Hesitation – Indicates the speaker's self-control during the conversation. Higher values suggest significant care and hesitation in speech, while low values indicate careless speaking.
Concentration – Indicates how focused and/or emotionally invested in the topic the speaker is.
Anticipation – Indicates the speaker's expectation for the listener's response. It may indicate interest, engagement, or an attempt to elicit a desired response through conscious manipulation.
Emotional Profile
Excitement – Indicates percentages of excitement levels detected throughout the recording.
Arousal – Indicates percentages of a profound interest in the topic of conversation (positive or negative), or arousal towards the conversation partner.
Uneasiness – Indicates percentages of uneasiness or embarrassment levels detected in the recording.
Logical Profile
Uncertainty – Indicates the speaker's certainty level. Lower values mean higher confidence, while high values suggest internal conflict and uncertainty.
Imagination – Indicates percentages of profound cognitive efforts and potential mental 'visualization' employed by the speaker.
Mental Effort – The detected percentages of mental effort intensities reflecting the level of intellectual challenge.
Mental Effort Efficiency – Measures two aspects of the thinking process: the level of mental effort and how efficient the process is. Low mental effort and high efficiency are optimal.
Atmosphere
Indicates the overall positive/negative mood tendency. A high percentage of low atmosphere suggests potential problems.
Discomfort
Indicates the speaker's level of discomfort and potential disappointment at the beginning of the call compared to the end.

Fig. 10: Risk Report: Emotions Profiles Section
Emotion Player
Note: Emotion Player is shown only if it was enabled in the Questionnaire settings (Questionnaires Management > General > Show Emotional Player).
This player combines all audio recordings included in the questionnaire within a single Emotion+Risk player and displays a playable, color-coded visualization of both the emotion detected across the audio recording, as well as risk indicators.
This dataset can demonstrate the significant emotions and risk indicators in every section of the session, with each emotion represented in its own color, providing a quick overview as well as the ability to play back significant sections:
- Risk: risk level detected within the reply, where red is the highest, orange – medium, and green – low.
- Emotions: the range of emotions within the replies. Blue – sad, Red – aggression, Joy – green. The brighter the color – the more intense emotions were detected.
- Stress: the level of stress during the replies. Stress is visualized by the intensity of the yellow color.
- Energy: the level of energy during the replies. Energy is visualized by the intensity of the grey color, where white is the highest.
The different recordings are shown on the player timeline, separated by a thin white line.
When a specific recording is being played, the name of the question is shown under the timeline.

Fig. 11: Risk Report: Emotion Player
Tags
This section displays all the tags added to the Questionnaire in its settings (Questionnaires Management > General > Tags).

Fig. 12: Risk Report: Tags Section
Personality Report
Personality assessment primary goal is to identify the respondent’s strengths and weaknesses, to identify the specific personality traits according to the responses to the Questionnaire.
The first section contains general information on the Report, such as:
- Report Name: name provided by the user to name the report.
- Test Type: the type of test as defined by AppTone back office.
- Date when the Report was generated.
Test Conclusion
Test Conclusion is the overall final conclusion based on the analysis results.
The Summary section provides the explanation made by the ChatGPT for the test conclusion.
Note: The Summary section is shown only if it was enabled in the Questionnaire settings (Questionnaires Management > GPT Instructions Tab > Enable ChatGPT Analysis).

Fig. 13: Personality Report: Test Conclusion Section
Personality Core Type
This section shows what type of personality the respondent demonstrated during the assessment.
It also contains a snapshot of the Emotional Diamond, which displays the range of most meaningful emotions that were captured during the survey.
Note: The Emotion Diamond section is shown only if it was enabled in the Questionnaire settings (Questionnaires Management > General Tab > Show Emotion Diamond).
There are four Personality Core Types:
1. Energetic Logical
Characterized by directness, decisiveness, and dominance, this style prefers leadership over followership. Individuals with this style seek management positions, exhibiting high self-confidence with minimal fear of consequences. Energetic and mission-focused, they are logical-driven risk-takers who passionately defend their beliefs and engage in arguments when disagreements arise.
2. Energetic Emotional
Thriving in the spotlight, this style enjoys being the center of attention. Individuals are enthusiastic, optimistic, and emotionally expressive. They place trust in others, enjoy teamwork, and possess natural creativity. While they can be impulsive, they excel at problem-solving and thinking outside the box. This personality type tends to encourage and motivate, preferring to avoid and negotiate conflicts. However, they may sometimes display recklessness, excessive optimism, daydreaming, and emotional instability.
3. Stressed Emotional
Known for stability and predictability, this style is friendly, sympathetic, and generous in relationships. A good listener, they value close personal connections, though they can be possessive. Suspecting strangers, they easily feel uncomfortable. Striving for consensus, they address conflicts as they arise, displaying compliance towards authority. Under high stress, they exhibit careful behavior, avoiding conflicts even at the cost of giving up more than necessary.
4. Stressed Logical
Precise, detail-oriented, and intensive thinkers, this style excels in analysis and systematic decision-making. They make well-informed decisions after thorough research and consideration. Risk-averse, they focus on details and problem-solving, making them creative thinkers. When faced with proposals, individuals with this style meticulously think through every aspect, offering realistic estimates and voicing concerns. While excellent in research, analysis, or information testing, their careful and complex thinking processes may pose challenges in leading and inspiring others with passion.

Fig. 14: Personality Report: Emotion Diamond Section
Full Report
The Full report section contains detailed analysis and personality assessment indicators for each question answered.
The questions are grouped according to Questionnaire topics.
Each Topic and question can be collapsed.
Questionnaire Topics
This section displays:
- Topic Name – set by the user in the Questionnaires Management > Topics & Questions Tab.
- State of Mind – indications of the respondent’s state per topic: Logical, Stress, Hesitation, Emotion Logic Balance, etc.

Fig. 15: Personality Report: Topic Section
Question
The Question section contains the indicators for each question of the topic, with the following details:
- Question number, text and Volume and Noise level icons next to them.
- Playback of the recording.
- Transcription of the audio reply, if available.
Note: If the question is masked as containing PII, the transcription will not be available.
- Strengths / Challenges section.

Fig. 16: Personality Report: Question Section
Strengths / Challenges
Strengths / Challenges section talks about whether the reply to the question seems to indicate that the topic is generally challenging for a person or whether this topic is actually a strength and a person is confident about what he is saying.
The section displays the following indicators:
- Overall Strengths level (muscle flex for strength
 ), where 5 icons are the highest level and 1 is the lowest, or Overall Challenges level (pushing rock uphill
), where 5 icons are the highest level and 1 is the lowest, or Overall Challenges level (pushing rock uphill  ), where 5 icons are the highest level and 1 is the lowest.
), where 5 icons are the highest level and 1 is the lowest. - Points for each 5 major states, with values from 0 to 5 (Confidence, Hesitation, Excitement, Energy, Stress).
- Personality traits section with a scale showing which traits/behavior a person is more inclined to:
- Authentic motivation vs Social conformity: whether a person is motivated and believes in what he is saying or is trying to give a right answer.
- Caution communication vs Open expression: this is like a self-filtering, whether a person is speaking freely and openly, without self judging.
- Emotion driven vs Logic driven: whether a person is guided more by emotions or logic.

- Key Emotions level captured within the reply (Sadness, Aggression, and Joy).

Profiles
This section shows the indicators of Emotions profiles and the state of a respondent for each of them.
Stress Profile
CLStress Score – Summarizes general stress level behavior and indicates the recovery ability from acute stress spikes.
Stress – Indicates how nervous or concerned the speaker is. Note that spikes of stress are common.
Extreme Stress Counters – Extreme stress counters track the number of extreme stress segments and consecutive stress portions detected in the call.
Mood Profile
Evaluation of mood detected. Percentage of Joy, Sadness, and Aggression.
Behavioral Profile
Hesitation – Indicates the speaker's self-control during the conversation. Higher values suggest significant care and hesitation in speech, while low values indicate careless speaking.
Concentration – Indicates how focused and/or emotionally invested in the topic the speaker is.
Anticipation – Indicates the speaker's expectation for the listener's response. It may indicate interest, engagement, or an attempt to elicit a desired response through conscious manipulation.
Emotional Profile
Excitement – Indicates percentages of excitement levels detected throughout the recording.
Arousal – Indicates percentages of a profound interest in the topic of conversation (positive or negative), or arousal towards the conversation partner.
Uneasiness – Indicates percentages of uneasiness or embarrassment levels detected in the recording.
Logical Profile
Uncertainty – Indicates the speaker's certainty level. Lower values mean higher confidence, while high values suggest internal conflict and uncertainty.
Imagination – Indicates percentages of profound cognitive efforts and potential mental 'visualization' employed by the speaker.
Mental Effort – The detected percentages of mental effort intensities reflecting the level of intellectual challenge.
Mental Effort Efficiency – Measures two aspects of the thinking process: the level of mental effort and how efficient the process is. Low mental effort and high efficiency are optimal.
Atmosphere
Indicates the overall positive/negative mood tendency. A high percentage of low atmosphere suggests potential problems.
Discomfort
Indicates the speaker's level of discomfort and potential disappointment at the beginning of the call compared to the end.
Fig. 17: Personality Report: Emotions Profiles Section
Emotion Player
Note: The Emotion Player section is shown only if it was enabled in the Questionnaire settings (Questionnaires Management > General Tab > Show Emotion Player).
Basically, it shows what happened emotionally in different parts of the recording in terms of Emotions, Stress, and Energy. The scale is color-coded and defines:
- Emotions: the range of emotions within the replies. Blue – sad, Red – aggression, Joy – green. The brighter the color – the more intense emotions were detected.
- Stress: the level of stress during the replies. Stress is visualized by the intensity of the yellow color.
- Energy: the level of energy during the replies. Energy is visualized by the intensity of the grey color, where white is the highest.
This player combines all audio recordings included in the questionnaire within a single Emotion only player.
The different recordings are shown on the player timeline, separated by a thin white line.
When a specific recording is being played, the name of the question is shown under the timeline.

Fig. 18: Personality Report: Emotion Player
Tags
This section displays all the tags added to the Questionnaire in its settings (Questionnaires Management > General > Tags).
Fig. 19: Personality Report: Tags Section
Personality + Risk Report
This type of report uses both the indicators for risk assessment and personality assessment. It consists of the same sections, with a slight difference in their display.
Let us consider the differences.
Key Strengths & Challenges
A mixed report has a separate section for Key Strengths & Challenges.
Note: It is possible that there may not be enough data to detect key Strengths & Challenges. In this case, the section will not be shown.
The section displays the top 3 Strengths & Challenges that were detected, and the relevant topic and question for each point.
The value from 1-5 of the strength/challenge is represented in icons (muscle flex icon for strength, pushing rock uphill icon for challenge).

Fig. 20: Personality + Risk Report: Key Strengths & Challenges Section
Full Report
The next difference is that in the full report, the question section contains both risk indicators and personality indicators.
Risk indicators:
- Risk Level for each topic.
- Question number is color-coded, according to the risk level detected.
- Risk Analysis section with risk indicators.

Fig. 21: Personality + Risk Report: Risk Indicators of the Question
Personality indicators:
- Strengths / Challenges section.

Fig. 22: Personality + Risk Report: Strengths / Challenges Section
Emotion Player
The player combines all audio recordings included in the questionnaire within a single Emotion only player.

Fig. 23: Personality + Risk Report: Emotion Player
Settings Tab
The Settings tab relates to Twilio Settings. In case you would like to use your own Twilio account for managing WhatsApp settings, you will have to fill in the fields with the corresponding values. Please see below how to do that.
About Twilio
Basically Twilio is a platform that manages sending of messages in WhatsApp to users to complete a questionnaire. To use Twilio's Messaging APIs with WhatsApp, you will need a WhatsApp-enabled phone number, also referred to as a WhatsApp Sender.
Please, refer to Twilio documentation to register your first WhatsApp Sender and to get all the details on configuring the Twilio account:
Apptone Settings Tab

In case you wish to use your own Twilio account, please complete the following steps:
1. Create and configure your Twilio account.
2. Use a toggle to turn on Custom settings in the Apptone settings page.
3. Fill in the fields:
- WhatsApp Phone Number is the WhatsApp Sender phone number from which messages will be sent to users who will complete the questionnaires.
To create a WhatsApp sender in Twilio:
3.1.1 Open your Twilio account console https://console.twilio.com/.
3.1.2 Go to Explore Products > Messaging section.
3.1.3 Go to Senders subsection > WhatsApp Senders and select Create new sender.

3.1.4 Follow the steps on the screen to complete the New sender creation.
The new sender will be displayed in the list of your senders.
3.1.5 In the AppTone settings page fill in the WhatsApp Phone Number field with this sender phone number.

- Account SID relates to the authentication in the Twilio platform. The Account SID value can be found in the Account info section of your Twilio account.

- Messaging Service Sid is the identification number of the messaging service.
To get this value you need first to create such a service in your Twilio account:
3.2 Go to Messaging > Services in Twilio console and select Create Messaging Service.

3.2.2 Follow the instructions on the screen, and make sure you select the needed Sender in Step 2, which number you enter in the filed WhatsApp Phone Number in Apptone settings page.

3.2.3 After the Messaging Service is created, you will see it in the list of Messaging Services. Click on the needed service to get its SID.

3.2.4 Paste this value into the Messaging Service Sid field of the Apptone settings page.
4. Select Save to save the changes.

After you save the changes the Webhook URL field will be filled out automatically.
5. Copy Webhook URL field value and paste into the field Webhook url for incoming messages field of your WhatsApp Sender Endpoint confuguration page.
5.1 Go to Messaging > Senders > WhatsApp senders, and select the needed sender.
5.2 Select Use webhooks configuration.
5.3 Paste the value from Apptone settings page into the Webhook url for incoming messages field.

It's done! Twilio configuration is completed.
Message templates
This settings section relates to the message templates sent to the users, i.e. you can create and send your own Introduction / Retry / Closing / Cancellation (Pull Back) / Failure messages.
You can create the templates in the Apptone account and manage them in the Twilio account.
1. Select Add to add a template.
2. Fill in the form.and select Save.

The new template will be displayed in the list with the corresponding status.
3. Go to Messaging > Content Template builder to configure added templates in your Twilio account.

Other important Twilio settings
For security reasons we also recommend enabling the HTTP Basic Authentication for media access to protect your data.
To do that go to Settings > General in your Twilio account page.

Developer's zone
Emotion Logic Open Source and Postman sample collections
Clone Emotion Logic UI library
This repository is our open-source library for all UI elements used on our reports.
git clone https://gitlab.com/emotionlogic-sky/emotionlogic-ui.gitClone Emotion Logic open source sample application
This repository is sample application that demonstrate the use ofour open source UI library
git clone https://gitlab.com/emotionlogic-sky/emotionlogic-api-examples.gitPostman sample collections
FeelGPT API samples
This is a sample postman collection analyze audio files using FeelGPT advisors
Download FeelGPT API samples Postman collection
AppTone API samples
This is a sample postman collection to send tests (questionnaire)
Download AppTone API samples Postman collection
Basic Analysis API samples
This is a sample postman collection to send audio files for analysis. Mainly, the request cotnains an audio file and some extra parameters, and the response contains a JSON with analysis results
Download Analysis API samples Postman collection
Audio Analysis API
Introducing Emotion-Logic Cloud Services
Emotion-Logic offers Cloud Services as a convenient alternative to self-hosting, making it easier than ever to implement our genuine emotion detection technology. With Emotion-Logic Cloud Services, you gain access to our advanced emotion detection system without the need to install or manage Docker containers on your own servers.
Why Choose Emotion-Logic Cloud Services?
Fast Deployment
Get started quickly without complex installation processes or server setup.
Hassle-Free Server Management
We handle server management, maintenance, and updates, allowing you to focus on your core projects and applications.
Perfect for Testing, Development, and Small-Scale Use
Ideal for experimenting with our technology, developing new applications, or supporting small-scale use cases.
Pay-Per-Use Pricing
While the cost per test may be higher than self-hosting, our pay-per-test pricing model ensures you only pay for what you use, making it a cost-effective solution for many projects.
Getting Started
To begin using Emotion-Logic Cloud Services, simply create an account on our platform, start a new project, and create the application you need. A set of API keys and passwords will be automatically generated for you. This streamlined process provides seamless access to our cloud-based API, enabling you to integrate our genuine emotion detection technology effortlessly into your projects.
API Options for Flexible Emotion Detection
Emotion-Logic offers a variety of API options to suit different needs, ensuring that our genuine emotion detection technology is adaptable for a wide range of use cases:
Pre-Recorded File Analysis
Analyze specific conversations or feedback from a single audio file.
Questionnaire (Multi-File Structure) Analysis
Process multiple questionnaires or survey responses, delivering emotion detection insights for each file.
Streaming Voice Analysis
Enable real-time emotion detection for live interactions or voice-controlled devices.
Explore "Analyze Now" APIs for Advanced Applications
For more complex use cases, our "Analyze Now" APIs—including FeelGPT, AppTone, and the Emotional Diamond Video Maker—combine Layered Voice Analysis (LVA), Speech-to-Text (S2T), and Generative AI to deliver a complete 360-degree analysis. These APIs require an API User to be created and provide enhanced capabilities for deeper emotional insights, textual context integration, and generative interpretations.
These versatile options make it easy to integrate Emotion-Logic into diverse applications, enabling more engaging, emotionally aware user experiences while supporting advanced business needs.
Pre recorded files API requests
Pre-recorded audio analysis requests
Offline analysis requests
Analyzing an uploaded media file
Test analysis request (Questionnaire set of recordings)
Analysis request with an uploaded file
This route accepts a file on a form data and returns analysis results.
Docker URI: http://[docket-ip]/analysis/analyzeFile
Cloud URI: https://cloud.emlo.cloud/analysis/analyzeFile
Method: POST
| Header | Value | Comment |
| Content-Type | multipart/form-data |
Common request params
| Parameter | Is Mandatory | Comment |
| file | Yes |
A file to upload for analysis |
| outputType | No |
Analysis output format. Can be either "json" or "text" json - most common and useful for code integration. This is the default response format text - CSV-like response. |
|
sensitivity
|
yes |
May be "normal", "low" or "high". Normal Sensitivity: Ideal for general use, providing a balanced approach to risk assessment. |
|
dummyResponse
|
No |
For development purpose. If "true", the response will contain dummy values, and the request will not be charged |
|
segments
|
No |
By default, the analysis process divids the audio file into segments of 0.4 to 2.0 seconds length. It is possible to pass an array of segments-timestamps, and the analysis will follow these timestamps when dividing the audio. The "segments" attribute is a JSON string wich represents an array of elements, where each element has a "start" and "end" attribute. channel : The channel number in the audio start : the offset-timestamp of the segment start time end : the offset-timestamp of the segment end time
Example: [{"channel": 0,"start" : 0.6,"end" : 2.5},{"channel": 0,"start" : 3,"end" : 3.5}] |
|
requestId
|
No |
A string, up to 36 characters long. The requestId sent back to the client on the response, so clients can associate the response to the request |
|
backgroundNoise
|
No |
0 - Auto backbground noise calculation (same as not sending this param) Any other number - the background noise value to use for analysis |
Additional parameters for cloud-specific request
| Parameter | Is Mandatory | Comment |
| apiKey | On cloud-requests only |
For cloud-request only. This is the application API key created on the platfrom |
| apiKeyPassword | On cloud-requests only |
For cloud-request only. This is the application API key password created on the platfrom |
| consentObtainedFromDataSubject | On cloud-requests only |
For cloud-request only. must be true. The meaning of this param is that you got permission from the tested person to be analyzed |
|
useSpeechToText
|
No |
If "true", and the application allowed for speech-to-text service, a speech-to-text will be executed for this request (extra cost will be applied) |
Example for analysis request to EMLO cloud

Questionnaire-based risk assessment
This route provides risk assessment based on a set of topics to analyze.
Each file in the request may be associated with one or more topics, and for each topic, a question may have a different weight.
Docker URI: http://[docket-ip]/analysis/analyzeTest
Cloud URI: https://cloud.emlo.cloud/analysis/analyzeTest
Method: POST
| Header | Value | Comment |
| Content-Type | application/json |
Common request params
| Parameter | Is Mandatory | Comment |
| url | Yes |
The URL of the file to be analyzed. This URL must be accessible from the docker |
| outputType | No |
Analysis output format. Can be either "json" or "text" json - most common and useful for code integration. This is the default response format text - CSV-like response. |
| sensitivity | Yes |
May be "normal", "high" or "low". Normal Sensitivity: Ideal for general use, providing a balanced approach to risk assessment. |
| dummyResponse | No |
For development purpose. If "true", the response will contain dummy values, and the request will not be charged |
| segments | No |
By default, the analysis processs divids the audio file into segments of 0.4 to 2.0 seconds length. It is possible to pass an array of segments-timestamps, and the analysis will follow these timestamps when dividing the audio. The "segments" attribute is an array of elements, where each element has a "start" and "end" attribute. channel : The channel number in the audio start : the offset-timestamp of the segment start time end : the offset-timestamp of the segment end time |
| requestId | No |
A string, up to 36 characters long. The requestId sent back to the client on the response, so clients can associate the response to the request |
The questionnaire section of the request includes the "isPersonality" flag that can be set as "true" or "false" and has effect in HR applications datasets.
Use "true" to mark a question for inclusion into the personality assessment set, and into the Strengths/Challanges analysis section available in the HR datasets.
Example for analysis request to the docker

Additional parameters for cloud-specific request
| Parameter | Is Mandatory | Comment |
| apiKey | On cloud-requests only |
For cloud-request only. This is the application API key created on the platfrom |
| apiKeyPassword | On cloud-requests only |
For cloud-request only. This is the application API key password created on the platfrom |
| consentObtainedFromDataSubject | On cloud-requests only |
For cloud-request only. must be true. The meaning of this param is that you got permission from the tested person to be analyzed |
|
useSpeechToText
|
No |
If "true", and the application allowed for speech-to-text service, a speech-to-text will be executed for this request (extra cost will be applied) |
Example for analysis request to EMLO cloud

API response examples
Human Resources








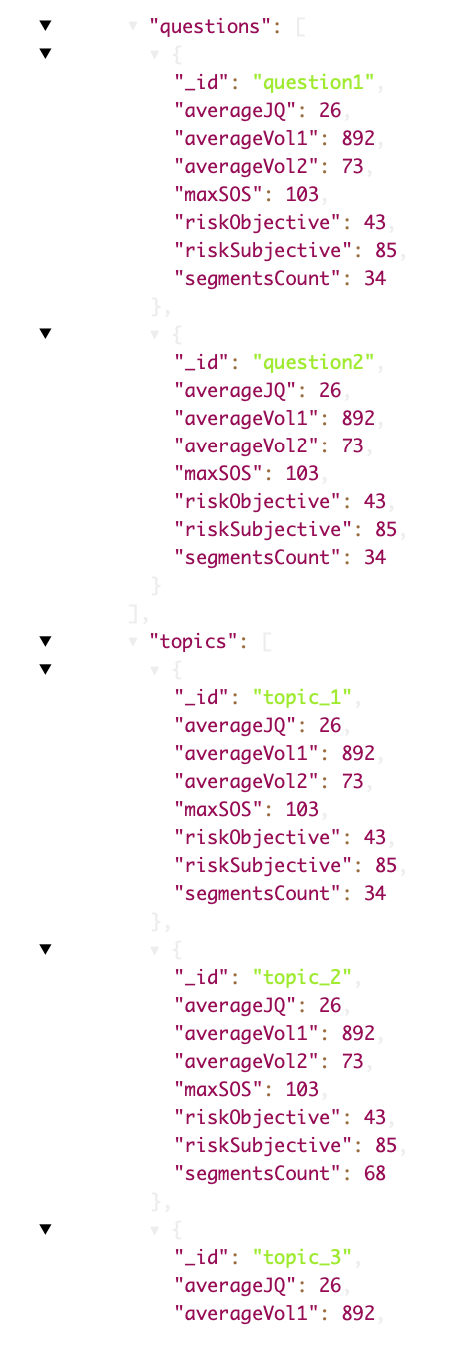










Standard call center response sample
2121




Call center sales response sample






Call center risk sample response






API Error and warning codes
Errors table
| Error code | Description |
| 1 | A renewal activation code is needed soon |
| -100 | An internal error occurred in the license server initialization process |
| -102 | A protection error was detected |
| -103 |
WAV file must be 11025 sample rate and 16 or 8 bit per sample
|
| -104 | The requested operation is not allowed in the current state |
| -105 | The license requires renewal now, the system cannot operate anymore |
| -106 | The license limit was reached, and the system cannot process any more calls at this time |
| -107 | The docker is not activated yet and requires a new activation code to operate. Please set your API key and password in the Docker dashboard. |
| -108 | The system identified the system's date was changed - the time change invalidated the license |
| -110 | An unspecified error occurred during the process |
| -111 |
Invalid license key/activation code
|
| -112 | The system identified unauthorized alteration of the license records |
| -114 | No credits left |
| -115 | The number of concurrent processes is more the defined in the license |
| -116 | Invalid parameter in request |
| -118 | Audio background level too high |
| -119 | Activation code expired |
| -120 | The license does not support the requested analysis |
| -999 | Another server instance is currently using the License file. The server cannot start |
Warnings table
| Warning code | Description |
| 101 | Audio volume is too high |
| 102 | Audio volume is too low |
| 103 | Background noise is too high |
"Analyze Now" APIs
Introduction to the "Analyze Now" APIs
The "Analyze Now" APIs in the Emotion Logic Developers' Zone offer advanced, integrated solutions designed to go beyond basic LVA analysis. These APIs combine Layered Voice Analysis (LVA), Speech-to-Text (S2T), and Generative AI to deliver comprehensive insights tailored for complex applications.
Currently supporting services like FeelGPT, AppTone, and the Emotional Diamond Video Maker, these APIs enable deeper emotional and cognitive analysis, textual context integration, and powerful generative interpretations. Unlike the standard LVA APIs, the "Analyze Now" APIs require you to create an API USER to enable access and manage service-specific configurations.
This advanced functionality makes "Analyze Now" ideal for scenarios that demand holistic voice and text-based analysis, enabling seamless integration into your workflows for actionable insights.
AnalyzeNow Applications Authentication
AnalyzeNow applications uses basic authenitcation, and requires AnalyzeNow API Key and password.
- Create AnalyzeNow API Key and password
- Eeach AnalyzeNow request must contain HTTP basic authentication header
HTTP Basic Authentication generic Javascript sample code
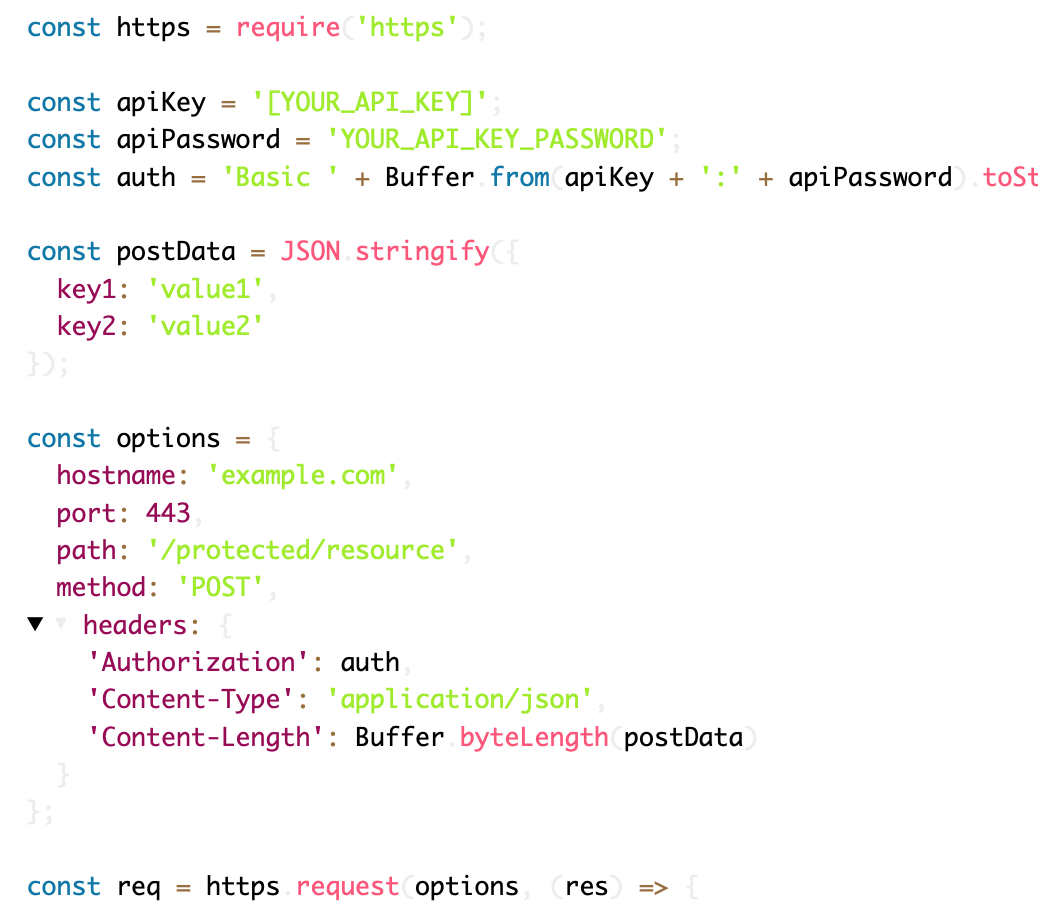

Analyze Now API Key
Analyze Now API requires basic authentication using API Key and API Password.
Creating Analyze Now API Key and Password
- On the main menu, select "Analyze Now API Keys" under "Account"

-
Click "Add Analyze Now API Key"
-
On the "Add API Key" popup, set the password and name and select "Organiation User" role, and save.

- Use the API Key and the password you provided for the authenitcation process
Analyze Now Encrypted Response
You can instruct the Analyze Now API to encrypt its webhook responses by passing an “encryptionKey” parameter in the Analyze Now application’s requests.
When the “encryptionKey” field is added to the request, the “payload” part of the webhook will be encrypted.
Here is a JavaScript sample code to decrypt the payload part:
Obtaining advisor id
FeelGPT AnalyzeFile API endpoint requires an advisor-id as part of the request. This document explains how to get obtain an advisor-id
1. On FeelGPT, click "Let's Start" button on your prefered advisor

2. The advisor-id it located at the top-right of the screen

3. Copy the advisor-id to the clipboard by clicking the "copy" icon.
FeelGPT Get Advisors List
advisors is an HTTP GET enpoint to retrieve a list of all available advisors.
A call to advisors endpoint requires basic authentication. Please refer to Analyze Now Authentication
Here is a sample Javascript code to fetch the advisors list
analyze is an HTTP POST enpoint to start an asynchronus process to analyze an audio file.
The analysis process status reported though a webhook calls from FeelGPT analyzer.
A call to analyze endpoint requires basic authentication. Please refer to Analyze Now Authentication
It is recommended to encrypt the callback payload data by passing an "encryptionKey" string value on the request. Read more
Learn how to obtain the advisor-id for your prefered advisor Here
Parameters
| Param Name | Is Mandatory | Comments |
| audioLanguge | yes | The spoken language in the audio file |
| file | yes | a file to analyze |
| analysisLanguage | yes | The language FeelGPT will use for the analysis report |
| statusCallbackUrl | yes | A webhook URL for status calls from FeelGPT analysis engine |
| sendPdf | no | I "true", send the analysis results in PDF format on analysis completion. The file on the callback is based64 encoded |
| encryptionKey | no | Encryption key to encode the "payload" field on webhook callback |
See NodeJS sampke code
Install required libraries
npm install axios form-data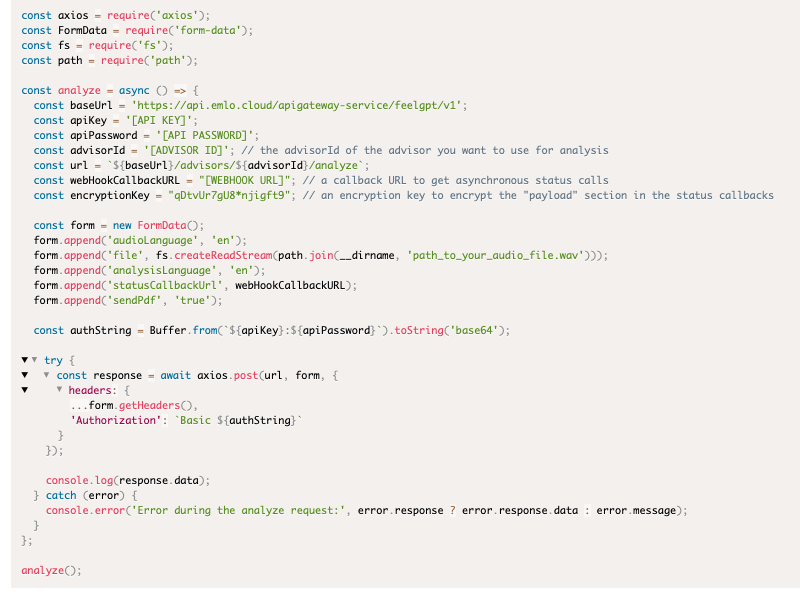
Explanation
- Importing Libraries:
- `axios` for making HTTP requests.
- `form-data` for handling form data, especially for file uploads
- `fs` for file system operations
- `path` for handling file paths.
- Creating the Form Data:
- A new instance of `FormData` is created.
- Required fields are appended to the form, including the audio file using `fs.createReadStream()` to read the file from the disk.
- Making the Request:
- The `axios.post()` method sends a POST request to the specified URL.
- Basic authentication is used via the `auth` option.
- `form.getHeaders()` is used to set the appropriate headers for the form data.
- Handling the Response:
- The response is logged to the console.
- Any errors are caught and logged, with detailed error information if available
- Replace `'path_to_your_audio_file.wav'` with the actual path to your audio file. This code will send a POST request to the "analyze" endpoint with the required form data and handle the response accordingly.
Response Structure
Upon request reception, FeelGPT validate the request parameters. For a valid request FeelGPT will return a "reportId" identifier to be used when recieving asynchronous status updates.
For invalid parameter the response will return an error code and message which indicates the invalid param.
Sample response for a valid request
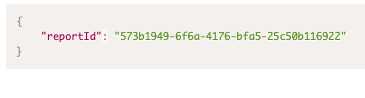
Sample response for a request with an invalid parameter

Once a valid request accepped on FeelGPT, it starts sending status update to the URL provided on "statusCallbackUrl" parameter.
Sample status callback data
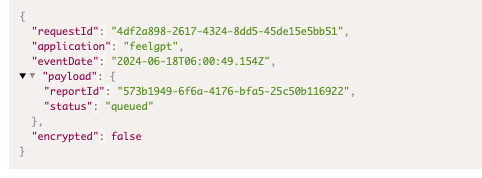
application: always "feelgpt".
eventDate: Time of the event in GMT timezone
payload: contain the actual event data
payload/reportId: The reportId that was provided on the response for the analysis request
payload/status: The current analysis status
encrypted: true of "encryptionKey" parameter sent on the analysis request
Avaialble Status
queued - The analysis request was successfully accepted, and queud for analysis
transcripting - The audio is now on transcription
analyzing - FeelGPT analyze the audio for emotions
completed - The report is ready. the "result" data contains the analysis data
pdfReady - If a PDF report was requested on the request, the payload for this status contains a PDF file in Base64 encoding
AppTone Get Questionnaires List
questionnaires is an HTTP GET enpoint to retrieve a list of all available questionnaires by filter.
A call to advisors endpoint requires basic authentication. Please refer to Analyze Now Authentication
Here is a sample Javascript code to fetch the questionnaires list
Install required libraries
npm install axiosAnd the actual code

Available filters for questionnaires endpoint
query - filter by the questionnaire name
languages - filter by supported languages
Response
The response is a list of questionnaires that matching the search criteria

Fields
name - The questionnaire name
language - The questionnaire language
description - The questionnaire description
apptoneQuestionnaireId - The questionnaire id
AppTone Send Questionnaire To Customer
sendToCustomer is an HTTP POST enpoint to start an asynchronus test interaction with a user.
The sendToCustomer process status reported though a webhook calls from AppTone service.
A call to sendToCustomer endpoint requires basic authentication. Please refer to Analyze Now Authentication
It is recommended to encrypt the callback payload data by passing an "encryptionKey" string value on the request. Please read more
Sample NodeJS for sendToCustomer
Install required libraries
npm install axiosAnd the actual code

Response Structure
Upon request reception, AppTone validate the request parameters. For a valid request AppTone will return a "reportId" identifier to be used when recieving asynchronous status updates.
For invalid parameter the response AppTone will return an error code and message which indicates the invalid param.
Sample response for a valid request
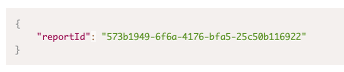
Sample response for a request with an invalid parameter

Once a valid request accepted on AppTone, it starts sending status update to the URL provided on "statusCallbackUrl" parameter.
Sample status callback data
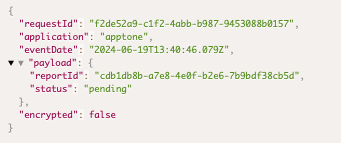
Params on status callback
application: always "apptone".
eventDate: Time of the event in GMT timezone
payload: contain the actual event data
payload/reportId: The reportId that was provided on the response for the sentToCustomer request
payload/status: The current analysis status
encrypted: true of "encryptionKey" parameter sent on the sentToCustomer request
Avaialble Statuses
pending - The test was sent to the customer
running - The customer is running the test. This status comes with "totalMessages" and "receivedMessages" params which indicates the running progress
analyzing - AppTone analyze the test
completed - The report is ready. the "analysis" data contains the analysis data
In case an error happen during the test run, a relevant error status will be sent

AppTone Cancel Test Run
cancel endpoint abort a test before its running completed
Install the required libraries
npm install axiosActual code

In case the reportId does not exists, or was already cenceled, AppTone will respond with an HTTP 404 status
AppTone Download Report PDF
downloadPdf is an HTTP POST asynchronous enpoint to create and downalod the report in a PSF format.
The downloadPdf send process status report though a webhook calls from AppTone service.
A call to downloadPdf endpoint requires basic authentication. Please refer to Analyze Now Authentication
It is recommended to encrypt the callback payload data by passing an "encryptionKey" string value on the request. Read more
Sample NodeJS code for downloadPdf
Install required libraries
npm install axios fsAnd the actual code

Response Structure
Upon request reception, AppTone validate the request parameters. For a valid request AppTone will return a "reportId" identifier to be used when recieving asynchronous status updates.
For invalid parameter the response AppTone will return an error code and message which indicates the invalid param.
Sample response for a valid request

Sample response for a request with an invalid parameter

Once a valid request accepted on AppTone, it will send a status updates to the URL provided on "statusCallbackUrl" parameter.
Sample status callback data with report PDF
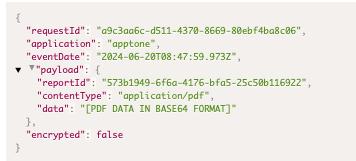
Params on status callback
application: always "apptone".
eventDate: Time of the event in GMT timezone
payload: contain the actual event data
payload/reportId: The reportId that was provided on the response for the sentToCustomer request
payload/contentTyp": always "application/pdf"
payload/data: The PDF file content in Base64 encoding
encrypted: true of "encryptionKey" parameter sent on the downloadPdf request
Errors callback
In case an error happen during the test run, a relevant error status will be sent
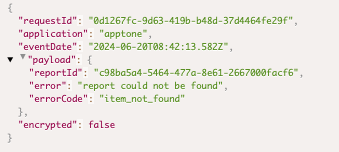
Docker installation and maintenance
System requirements
The docker runs on Linux Ubuntu 22.04 or later.
Installing docker software on the server
UBUNTU Server
Copy and paste the following lines to the server terminal window, then execute them
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get -y install docker-ce docker-ce-cli containerd.io docker-compose-pluginRed Hat Linux
copy and paste the following lines to the server terminal window, then execute them
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
sudo systemctl enable docker.service
sudo systemctl start docker.serviceInstalling Emotion Logic docker
copy and paste the following lines to the server terminal window, then execute them
docker run -d --restart unless-stopped -p 80:8080 -p 2259:2259 --name nms-server nemesysco/on_premisesThe docker will listen on port 80 for offline file analysis, and on port 2259 for real-time analysis

Activating the docker
Activating the docker is done by setting the API Key and API Key Password. Both are generated on the applications page
- Open the docker dashboard: http://[docker-ip]/
- On the docker dashboard set the API key and password and click “Activate”. This will
connect the docker to your account on the platform and get the license. - The docker will renew its license on a daily basis. Please make sure it has internal
access. - Now you can start sending audio for analysis
Updating docker version
The docker periodically checks for new versions and will perform an automatic upgrade for mandatory versions.
You can manually check for mandatory and recommended updates by clicking the "Check Updates" button.
Docker Management
Docker installation and maintenance
System requirements
The docker runs on Linux Ubuntu 22.04 or later.
Installing docker software on the server
UBUNTU Server
Copy and paste the following lines to the server terminal window, then execute them
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get -y install docker-ce docker-ce-cli containerd.io docker-compose-plugin
Red Hat Linux
copy and paste the following lines to the server terminal window, then execute them
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
sudo systemctl enable docker.service
sudo systemctl start docker.serviceInstalling Emotion Logic docker
copy and paste the following lines to the server terminal window, then execute them
docker run -d --restart unless-stopped -p 80:8080 -p 2259:2259 --name nms-server nemesysco/on_premisesThe docker will listen on port 80 for offline file analysis, and on port 2259 for real-time analysis
Activating the docker
Activating the docker is done by setting the API Key and API Key Password. Both are generated on the applications page
- Open the docker dashboard: http://[docker-ip]/
- On the docker dashboard set the API key and password and click “Activate”. This will
connect the docker to your account on the platform and get the license. - The docker will renew its license on a daily basis. Please make sure it has internal
access. - Now you can start sending audio for analysis
Updating docker version
The docker periodically checks for new versions and will perform an automatic upgrade for mandatory versions.
You can manually check for mandatory and recommended updates by clicking the "Check Updates" button.
Docker conducts regular checks for new versions and will automatically upgrade when mandatory versions are available. However, it does not initiate automatic upgrades for non-mandatory versions. You have the option to manually check for mandatory and recommended updates by clicking the 'Check Updates' button
Removing EMLO docker image
Sometimes it is required to completely remove EMLO docker. In order to do that, it is required to first delete the container, then the image
remove the container
1. list all containers
sudo docker container ls
2. stop the container
sudo docker stop [CONTAINER_ID]
3. delete the container
sudo docker rm [CONTAINER_ID]remove the image
1. list the images
sudo docker image ls
2. delete the docker
sudo docker image rm [IMAGE_ID]Remove All
Stop all containers on the server, than delete all containers and images
docker stop $(docker ps -q) && docker rm -f $(docker ps -aq) && docker rmi -f $(docker images -q)Stop/Start EMLO docker image
Sometimes it is required to stop or restart EMLO docker. In order to do that, it is required to stop the container
Stop the container
1. list all containers
sudo docker container ls2. stop the container
sudo docker stop [CONTAINER_ID]Start the container
1. list all containers
sudo docker container ls2. start the container
sudo docker start [CONTAINER_ID]Emotion Logic analysis docker version history
| Version | Release date | Mandatory for | Whats new? |
|
1.6.38
|
2024-08-15 |
Not Mandatory |
|
|
1.6.37
|
2024-07-22 |
Not Mandatory |
|
|
1.6.36
|
2024-06-11 |
Not Mandatory |
|
|
1.6.18
|
2024-03-18 |
Not Madatory |
|
|
1.6.14
|
2024-01-16 |
Not Madatory |
|
|
1.6.11
|
2024-01-01 |
Not Madatory |
|
|
1.6.10
|
2023-12-31 |
Not Madatory |
|
|
1.6.03
|
2023-12-13 |
Not Madatory |
|
|
1.6.01
|
2023-12-08 |
Not Madatory |
|
|
1.5.14
|
2023-12-06 |
Not Madatory |
|
|
1.5.7
|
2023-11-14 |
Not Madatory |
|
|
1.5.4
|
2023-11-07 |
Not Madatory |
|
|
1.5.3
|
2023-11-02 |
Not Madatory |
|
|
1.5.01
|
2023-10-26 |
Not Mandatory |
|
|
1.4.25
|
2023-10-17 |
Not Mandatory |
|
|
1.4.22
|
2023-09-15 |
Not Mandatory |
|
|
1.4.17
|
2023-09-04 |
Not Mandatory |
|
|
1.4.12
|
2023-08-14 |
Not Mandatory |
|
|
1.4.06
|
2023-08-01 |
1.3.92 and up |
|
|
1.4.01
|
2023-07-26 |
|
|
|
1.3.92
|
2023-07-05 |
Not Mandatory |
|
|
1.3.87
|
2023-06-07 |
Not Mandatory |
|
|
1.3.85
|
2023-06-05 |
Not Mandatory |
|
|
1.3.83
|
2023-05-31 |
Not Mandatory |
|
|
1.3.81
|
2023-05-22 |
Not mandatory |
|
|
1.3.80
|
2023-05-08 |
Not mandatory |
|
|
1.3.77
|
2023-04-27 | Not mandatory |
|
|
1.3.75
|
2023-04-18 | Not mandatory |
|
|
1.3.73
|
2023-04-17 | Not mandatory |
|
Real-time analysis (streaming)
Emotion-Logic's real-time API offers instant emotion detection for live interactions, making it ideal for voice-controlled devices, customer support, or any situation requiring immediate emotional understanding. With the real-time API, you can process streaming audio data and receive emotion detection results as events occur, enhancing responsiveness and user engagement.
Streaming (real-time) analysis is based on socket.io (Web Socket) and consists of several events that are sent from the client to the Docker container and vice versa.
Socket.io clients are supported by many programming languages.
Please refer to the full client implementation in the "stream-analysis-sample.js" file (NodeJS).
The analysis flow for a single call is as follows:
- The client connects to the Docker container.
- The client sends a "handshake" event containing audio metadata.
- The Docker container sends a "handshake-done" event, indicating that it is ready to start receiving the audio stream, or provides an error indication related to the "handshake" event.
- The client begins sending "audio-stream" events with audio buffers.
- The Docker container sends an "audio-analysis" event whenever it completes a new analysis.
- The client disconnects when the stream (call) is finished.
All code samples in this document are in NodeJS, but any socket.io client library should work for this purpose.
Connecting the analysis server
Connecting the analysis server is a standard client-side websockets connection

Handshake Event
Sent by: client
Event payload
| Parameter | Is Mandatory | Comments |
| isPCM | Yes | Boolean, “true” if the stream is PCM format. Currently, this param must be true |
| channels | Yes | A number, to indicate the number of channels. May be “1” or “2” |
| backgroundNoise | Yes | A number represents the background noise in the recording. The higher the number the higher the background noise. Standard recording should have value of 1000 |
| bitRate | Yes | A number represents the audio bit-rate. Currently 8 and 16 are supported |
| sampleRate | Yes | The audio sample rate. Supported values are: 6000, 8000, 11025, 16000, 22050, 44100, 48000 |
| outputType | No | Can be “json” ot “text”. Default is “json” |
Handshake Done
The docker sends this event as a response to a “handshake” event. On success, the payload will contain the streamId, on error it will hold the error data.
Event name: handshake-done
Sent by: analysis server
Event payload:
| Parameter | Comments |
| success | Boolean, "true” handshake succeed |
| errorCode | an error code, in case the handshake failed (success == false) |
| error | an error message, in case the handshake failed (success == false) |
Audio Stream
After a successful handshake, the client starts sending audio-buffers to the docker. The docker will asynchronously send the analysis results to the client.
Event: audio-stream
Sent by: client
Event payload: An audio buffer

Audio Analysis
As the client sends audio buffers, the docker starts analyzing it. Whenever the docker build a new segment, it pushes the segment analysis to the client using the “audio-analysis” event.
Event: audio-analysis
Sent by: docker
Event payload: Segment analysis data. Please refer to API Response for analysis details.
Fetch analysis report
At the end on the call, it is possible to send a "fetch-analysis-call" event to the docker.
The docker will respond with an "analysis-report-ready" event containing the call report (same report as accepted on a file-analysis call).
Event: fetch-analysis-call
Event parameters
| Parameter | Is Mandatory | |
| outputFormat | No | May be "json" (default) or "text" |
| fetchSegments | No | May be true (default) or false |
Analysis report ready
After sending a "fetch analysis report" event, the analysis server respond and "analysis report ready" event.
The response will contain the same analysis report as provided by a regular file analysis.
Event: analysis-report-ready
Sent by: analysis server

Sample code - avoid promises



Sample code - Using promises
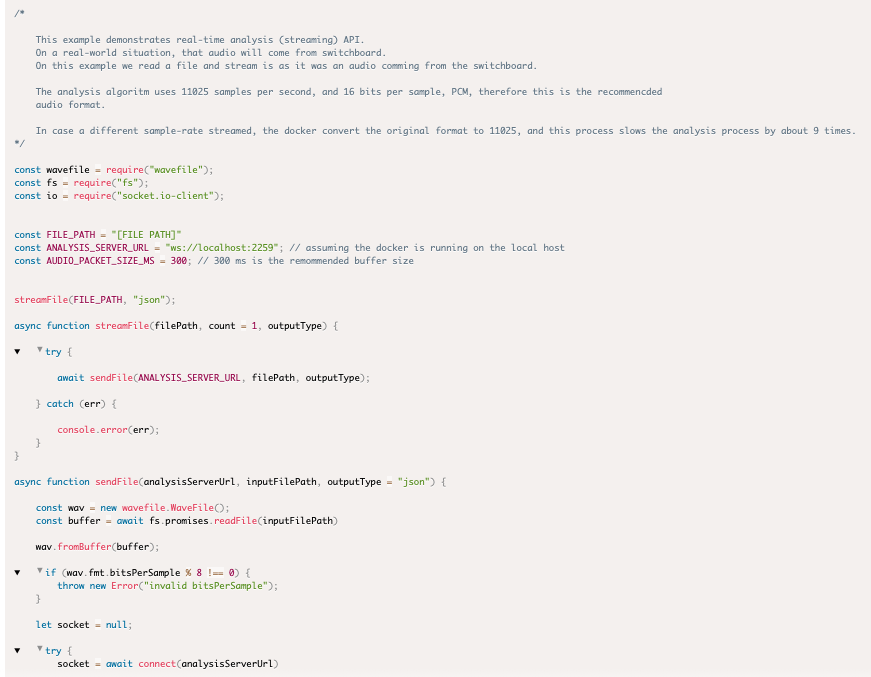




Emotion Logic docker supports integrations with 2 STT (Speech To Text) providers
- Deepgram
- Speechmatics
By setting your STT provider API Key, the Emotion Logic anlysis docker will sync its analysis to the STT results.
When activating STT on the docker, each analysis sigment will contain the spoken text at the time of the segment.
How to set STT provider API Key

1. Open the Docker dashboard and navigate to the “Integrations” tab.
2. If you do not have an account with one of the supported Speech-to-Text (STT) providers, please visit:
• Deepgram
3. Create an API Key with your chosen STT provider.
4. Enter the STT API Key in the appropriate field.
5. Save your changes.
6. Ensure that you include "useSpeechToText: true" in your analysis requests.
Release Notes: Version 7.32.1
New Features: • LOVE Values: Added all LOVE values to enhance the emotional analysis capabilities.
Improvements: • MostFanatic Function: Optimization of the MostFanatic function for better performance and accuracy.
• Passion Detection: Modified the SAF value function to improve the detection of passion.
• Strengths and Challenges: Function updated to relate to averages as a baseline, providing relative strengths and weaknesses. The function now includes “uneasy” and “arousal” metrics to keep the assessment relative.
Bug Fixes: • Channel Similarity: Fixed a bug related to similarity calculations between channels.
Updates:
• Excitement and Uncertainty: Updated the functions for Excitement and Uncertainty to align with new norms.
• BG Auto Test: Modified the BG auto test functionality. Tests are now disabled for segments shorter than 5 seconds. Users should utilize FIX BG or STT for segmentation in such cases.
Release Notes for LVA7 Tech. 7.30.1
Version Update:
Optimization: Improved CallPriority scores and call classifications tailored for call center scenarios.
Bug Fix: Resolved issues with time pointer shifts in lengthy files.
Modification: Updated FeelGPT protocol terminology to clarify message meanings (changed "Passion" to "arousal" and "passion peak" to "arousal peak").
Release Notes for LVA7 Tech. 7.29.3
We are excited to announce the release of LVA7, a significant update to our analytics platform. This version introduces several enhancements and fixes aimed at improving accuracy, usability, and comprehensiveness of risk assessments and personality insights. Here's what's new:
Enhancements:
Objective Risk Formula Optimization:
1. We've fine-tuned the Objective (OZ) risk formulas to better incorporate inaccuracy indicators, resulting in more nuanced risk assessments.
2. Users can expect a modest recalibration of risk scores, with a greater number of risk indicators and inaccuracies now being flagged.
3. For those preferring the previous version's risk evaluation, the option to revert is available by setting sensitivity: bwc1 for backward compatibility.
Introduction of Final Risk Score:
A new "Final Risk" score has been added to the risk summaries, amalgamating objective and subjective risk evaluations for a comprehensive overview.
When only one type of risk is assessed, the Final Risk score will reflect that singular assessment.
The calculation method for the Final Risk score in the Topics and Questions sections has been updated for enhanced accuracy.
Personality Assessment Enhancement: (In supported applications)
The questionnaire API now supports personality assessments at the question level.
Use isPersonality: true to designate a question for personality evaluation.
Use isPersonality: false to designate a question for risk assessment only.
Questions with a non-zero weight parameter will contribute to both personality and risk assessments. Set weight: 0 to exclude a question from risk evaluation.
Important Update Regarding isPersonality Setting:
To ensure a seamless transition and maintain backward compatibility, the isPersonality option will default to True in the current release. Be aware that this behavior is slated for a future change. We strongly recommend that users review and adjust their questionnaire settings accordingly to ensure accurate core competencies values analysis. Remember, only questions explicitly marked with isPersonality: true are factored into this analysis.
Bug Fixes:
Emotion Diamond Real-Time Values Correction:
An issue affecting the real-time values displayed on Emotion Diamond for channel 1 has been addressed, ensuring accurate emotional insight representation.
The old Nemesysco's cloud response and the new EmotionLogic response
| Nemesysco's cloud response | New Emotion-Logic response | Remarks |
|
"RISKREPT":[ |
{ |
The Topics Risk report is now more detailed and contains more items. Topic Name;Channel ID;Segment Count; Risk;Max SOS Topic Name is now "_id" "C0" - old Channel ID - this param was dropped from the new version Segment count maps to the new segmentsCount The old RISK maps to the new "riskObjective" and uses the same scale and values. "SOS" maps to the new "maxSOS" and have the same meaning and scales.
|
| "RISKREPQ":[ "Topic1;Question1;C0;1;22;75;10", "Topic1;Question2;C0;1;12;93;20", "Topic2;Question3;C0;2;84;100;30", "Topic2;Question4;C0;2;55;92;40" ], |
"reports": { "risk": { "questions": [ { "_id": "topic1", "averageJQ": 26, "averageVol1": 892, "averageVol2": 73, "maxSOS": 103, "riskObjective": 43, "riskSubjective": 85, "segmentsCount": 34 } ] } } |
The Questions Risk report is now more detailed and contains more items. Topic Name;Question Id;Channel ID;Segment Count; Risk;Max SOS Question Name is now "_id" "C0" - old Channel ID - this param was dropped from the new version Segment count maps to the new segmentsCount The old RISK maps to the new "riskObjective" and uses the same scale and values. "SOS" maps to the new "maxSOS" and have the same meaning and scales. |
| "EDPREPT":[ "Leadership;Leading by example;C0;1;25;1;38;1;20;13;83;100;100;41", "Leadership;Approach toward difficulties;C0;1;19;1;31;1;60;25;68;67;100;57", "Leadership;Leadership skills;C0;2;25;1;23;1;32;22;81;100;100;60", "Leadership;Influencing others;C0;2;38;1;24;1;34;23;81;68;98;42" ] |
Emotional Diamond data by question | |
| "SEG":[ "TotalSeg#;Seg#;TOPIC;QUESTION;Channel;StartPos;EndPos;OnlineLVA;OfflineLVA; Risk1;Risk2;RiskOZ;OZ1/OZ2/OZ3;Energy;Content;Upset;Angry;Stressed;COGLevel; EMOLevel;Concentration;Anticipation;Hesitation;EmoBalance;IThink;Imagin;SAF;OCA; EmoCogRatio;ExtremeEmotion;CogHighLowBalance;VoiceEnergy;LVARiskStress; LVAGLBStress;LVAEmoStress;LVACOGStress;LVAENRStress", "SEG1;0001;Leadership;Leading by example;C0;0.90;1.40;Calibrating... (-2);<OFFC01>;0;0; 145;4/3/1232;4;0;0;0;0;15;30;30;30;14;51;0;0;0;551;100;11;58;1356 / 66;0;0;0;0;0" ] |
Segments data by the selected application structure |
Initializing Docker with Environment Variables
In scenarios where Docker containers need to be initialized automatically—such as when deployed by Kubernetes—manual initiation through the Docker dashboard is not possible. Instead, the container can be configured to initialize itself automatically by passing the necessary environment variables.
Mandatory Environment Variables
To ensure proper authentication and functionality, the following environment variables must be provided:
• PLATFORM_APIKEY – API key for emlo.cloud
• PLATFORM_APIKEY_PASSWORD – Password for the emlo.cloud API key
To run the container with these variables, use the following command:
docker run --rm -p 8080:8080 -p 2259:2259 \
-e "PLATFORM_APIKEY=test" \
-e "PLATFORM_APIKEY_PASSWORD=test" \
--name nms-server nemesysco/on_premisesOptional Environment Variables
The following optional environment variables can be used to integrate with third-party services or modify the container’s behavior:
• DEEPGRAM_URL – Base URL for the Deepgram Speech-to-Text (STT) API
• STT_KEY – API key for Deepgram’s STT service
• SPEECHMATICS_KEY – API key for Speechmatics STT API
• WHISPER_BASE_URL – Base URL for Whisper STT API
• DISABLE_UI – A flag to disable the Docker UI. Assigning any value to this variable will disable the UI.
By configuring these variables appropriately, the container can be tailored to meet specific deployment needs.